Vượt qua bảo vệ Cloudflare: Các phương pháp hay nhất

Hôm nay chúng ta sẽ tìm hiểu xem có thể vượt qua bảo vệ Cloudflare hay không và cách làm điều đó mà không vi phạm pháp luật. Cloudflare là một công ty công nghệ lớn cung cấp các dịch vụ web cơ sở hạ tầng để bảo vệ các trang web, tuy nhiên các hệ thống của nó có khả năng chặn cả những hoạt động hoàn toàn hợp pháp: phân tích dữ liệu công khai hoặc quản lý nhiều tài khoản. Lý do là những tác vụ như vậy yêu cầu gửi nhiều yêu cầu mỗi giây và thường được tự động hóa để nâng cao hiệu quả — Cloudflare coi chúng là giống như bot và có khả năng gây hại. Như chúng ta sẽ thấy, các proxy xoay vòng kết hợp với các trình duyệt chống phát hiện và điện thoại đám mây giúp vượt qua những hạn chế này.
Cloudflare là gì: cơ sở hạ tầng web bảo vệ toàn cầu
Cloudflare sử dụng các hệ thống chống bot và chống gian lận tiên tiến — Web Application Firewall (WAF), Bot Management và Turnstile — để bảo vệ các trang web khỏi các cuộc tấn công DDoS, phân tích dữ liệu độc hại, chiếm đoạt tài khoản và spam. Các hệ thống này hoạt động như trung gian giữa máy khách và máy chủ, phân tích các dấu vân tay kỹ thuật số của trình duyệt (fingerprint), cấu hình TLS/HTTP và hành vi của người dùng để phân biệt lưu lượng hợp pháp với các tập lệnh tự động hóa.
Đọc bài viết của CyberYozh về các trình kiểm tra và trình phân tích cú phápđể tìm hiểu cách các nền tảng phát hiện và chặn hoạt động đáng ngờ
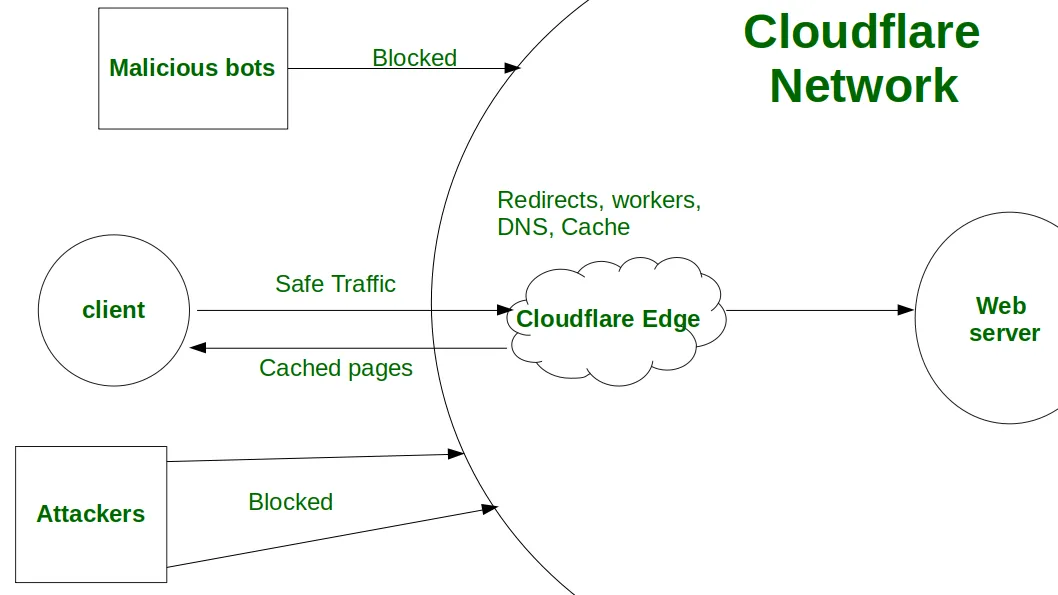
Nếu dấu vân tay kỹ thuật số của khách truy cập có vẻ đáng ngờ, Cloudflare sẽ khởi chạy các kiểm tra JavaScript hoặc Turnstile CAPTCHA để xác minh con người. Hệ thống cũng có thể chặn các địa chỉ IP có điểm tin cậy thấp, từ chối quyền truy cập vào trang web. Các hành động như web scraping, tự động hóa tài khoản và đăng quảng cáo hàng loạt, đặc biệt là ở dạng tự động hóa, trông không tự nhiên và giống như hành vi của bot — vì vậy Cloudflare thường chặn chúng, ngay cả khi chúng hoàn toàn hợp pháp.
Nhanh chóng kiểm tra điểm tin cậy của IP của bạn bằng cách sử dụng IP Checker từ CyberYozh để tránh bị chặn.
Web Application Firewall từ Cloudflare
Web Application Firewall (WAF) là một hệ thống bảo mật dựa trên đám mây bảo vệ các ứng dụng web và API bằng cách phân tích và lọc lưu lượng HTTP/HTTPS đến theo thời gian thực. Nó hoạt động như một trung gian giữa máy khách và ứng dụng, kiểm tra từng yêu cầu theo các bộ quy tắc (ruleset) để chặn hoạt động độc hại — tiêm SQL, tập lệnh trên nhiều trang web (XSS) hoặc các cuộc tấn công DDoS — đồng thời cho phép lưu lượng hợp pháp đi qua. WAF đánh giá các yêu cầu bằng nhiều phương pháp:
Phát hiện chữ ký: WAF so sánh lưu lượng đến với cơ sở dữ liệu chữ ký tấn công được cập nhật liên tục, ngay lập tức chặn các tải trọng khớp với các mối đe dọa được nhận dạng.
Quy tắc tùy chỉnh: Các quản trị viên có thể tạo các quy tắc cụ thể với cú pháp biểu thức linh hoạt để lọc lưu lượng theo địa chỉ IP, vị trí địa lý, đường dẫn URL, tiêu đề HTTP hoặc nội dung phần thân yêu cầu.
Học máy: Cloudflare áp dụng các thuật toán học máy để phát hiện các bất thường và mối đe dọa mới chưa có chữ ký đã biết.
Thứ tự thực hiện: Các yêu cầu được đánh giá theo một trình tự nhất định: trước tiên là các quy tắc IP Access, sau đó là các quy tắc tùy chỉnh và cuối cùng là các quy tắc giới hạn yêu cầu (Rate-limiting). Quy tắc đầu tiên kích hoạt một hành động kết thúc (ví dụ: Block hoặc Managed Challenge) sẽ dừng xử lý tiếp theo.
Để vượt qua những biện pháp bảo vệ này, các công ty có thể sử dụng các công cụ chuyên dụng — các trình duyệt chống phát hiện và mạng proxy bắt chước hành vi của người dùng thực.
Tìm hiểu thêm về tự động hóa web scraping — một thực tiễn điển hình yêu cầu proxy.
Công cụ phát hiện bot của Cloudflare
Cloudflare sử dụng một cách tiếp cận đa cấp để phát hiện và chặn lưu lượng bot độc hại, đồng thời đảm bảo quyền truy cập không bị cản trở cho người dùng hợp pháp và bot được xác minh (ví dụ: Googlebot). Các cơ chế phát hiện này được bao gồm trong các sản phẩm Cloudflare Bot Management và Super Bot Fight Mode, hàng ngày phân tích hàng tỷ yêu cầu trên mạng toàn cầu, liên tục cập nhật cơ sở dữ liệu mối đe dọa.
Tìm hiểu thêm về các thực tiễn tốt nhất về web scraping — trong bài viết của CyberYozh.
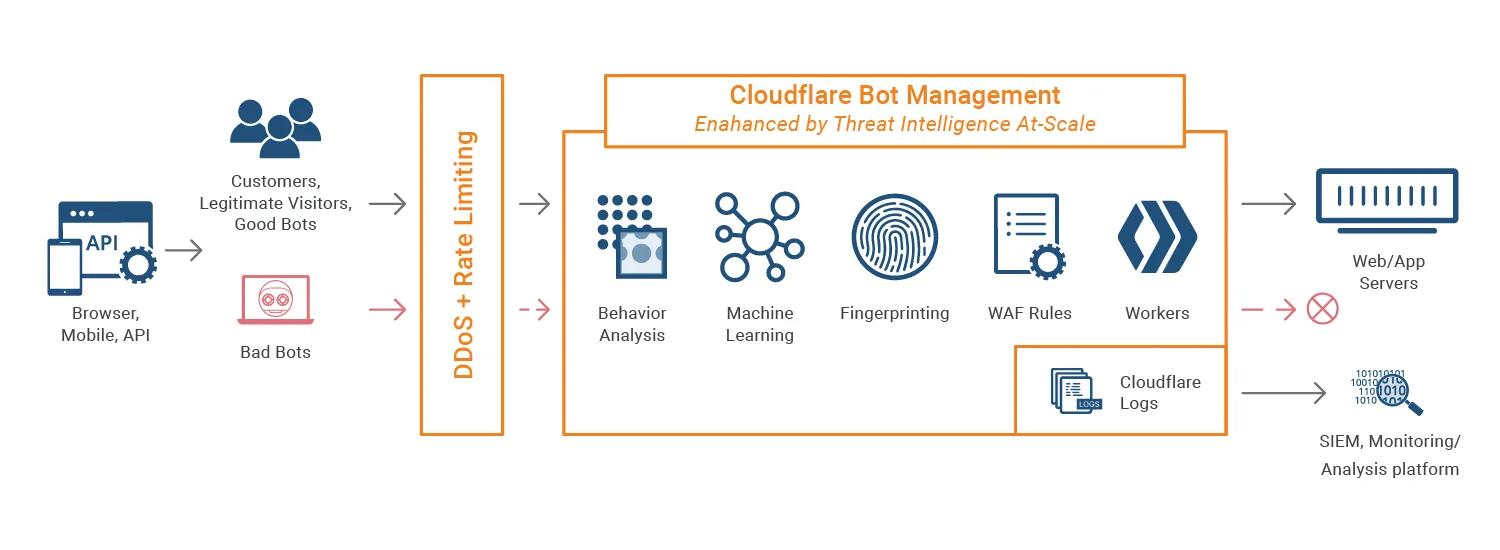
Khi một yêu cầu đến một trang web được bảo vệ bởi Cloudflare, nó được đánh giá theo thời gian thực bởi nhiều động cơ phát hiện. Mỗi yêu cầu cuối cùng được gán một Bot Score từ 1 (chắc chắn là tự động hóa) đến 99 (có khả năng là con người). Đây là cách nó hoạt động:
Động cơ heuristic kiểm tra các yêu cầu đến để tìm các dấu hiệu rõ ràng của tự động hóa (ví dụ: mã Python), danh tiếng IP xấu và tiêu đề HTTP bất thường. Nếu yêu cầu phù hợp với quy tắc heuristic, nó sẽ ngay lập tức được đánh dấu là bot.
Phân tích giao thức và dấu vân tay mạng — để xác nhận rằng yêu cầu đến từ một thiết bị thực thông qua một trình duyệt hợp pháp. Nếu tập lệnh cố gắng giả mạo User-Agent Chrome nhưng sử dụng dấu vân tay TLS không tương ứng với trình duyệt Chrome thực, Cloudflare sẽ phát hiện sự không phù hợp.
Động cơ học máy sử dụng mô hình hành vi được đào tạo trên một lượng lưu lượng khổng lồ từ mạng toàn cầu của Cloudflare để phát hiện các bất thường. Nó đánh giá quá trình phiên, tần suất yêu cầu và các mẫu lệch khỏi hành vi bình thường của con người, và gán Bot Score.
Kiểm tra tích cực (Turnstile và JS): Nếu Bot Score của yêu cầu có vẻ đáng ngờ thấp nhưng không yêu cầu chặn rõ ràng, Cloudflare sẽ phát hành Managed Challenge hoặc kiểm tra Turnstile để đánh giá hành vi ở cấp độ ứng dụng.
Kết quả là các yêu cầu có Bot Score thấp, không được đánh dấu là bot được xác minh, hoặc bị chặn ngay lập tức, hoặc vượt qua kiểm tra CAPTCHA. Các yêu cầu tự động hóa hàng loạt, đặc trưng cho các quy trình kinh doanh khác nhau, có thể rơi vào danh mục này.
Tìm hiểu về xoay vòng IP để ngăn chặn các cuộc chặn và cách điều này ảnh hưởng đến Bot Score.
Có hợp pháp không khi vượt qua Cloudflare?
Cloudflare bảo vệ các trang web khỏi truy cập trái phép và các yêu cầu giống như các cuộc tấn công DDoS. Vậy có hợp pháp không khi cố gắng vượt qua các lớp bảo vệ này? Câu trả lời tùy thuộc vào mục đích của bạn: nếu bạn không vi phạm Điều khoản sử dụng của các trang web và áp dụng các phương pháp vượt qua cho các mục đích kinh doanh hợp pháp — điều đó là hợp pháp. Ví dụ, việc vượt qua bảo vệ Cloudflare có thể cần thiết cho các nhiệm vụ sau:
Web scraping: Thu thập dữ liệu về giá cả của đối thủ cạnh tranh, danh mục sản phẩm và xu hướng thị trường từ các trang web công khai để điều chỉnh chiến lược định giá của công ty và duy trì khả năng cạnh tranh.
Quản lý phương tiện truyền thông xã hội: Tổng hợp tâm trạng công khai, quản lý nhiều tài khoản thương hiệu và giám sát các đề cập đến thương hiệu trên các nền tảng khác nhau bằng cách sử dụng các công cụ tự động hóa mà không kích hoạt các khóa bảo mật.
Phân tích dữ liệu khách hàng: Thu thập các đánh giá và phản hồi công khai từ các nền tảng thương mại khác nhau để phân tích tâm trạng của người tiêu dùng và cải thiện các chu kỳ phát triển sản phẩm.
Quảng cáo Internet: Xác minh vị trí quảng cáo, phát hiện gian lận liên kết và kiểm soát hiển thị chính xác của các chiến dịch bản địa hóa ở các khu vực khác nhau bằng cách sử dụng các mạng proxy tự động hóa.
Giám sát SEO: Theo dõi xếp hạng từ khóa, giám sát các liên kết ngược của đối thủ cạnh tranh và kiểm toán các trang kết quả tìm kiếm (SERP) trên toàn thế giới để tối ưu hóa kết quả tiếp thị kỹ thuật số.
Tổng hợp giá vé du lịch: Giám sát đồng thời nhiều trang web của hãng hàng không và khách sạn để cung cấp cho người tiêu dùng các bản so sánh giá tổng hợp cập nhật và thông tin về tính khả dụng đặt phòng theo thời gian thực.
Trong nhiều trường hợp, việc vượt qua Cloudflare là cách duy nhất để hoàn thành công việc, vì bảo vệ của nó chặn các quy trình gửi các yêu cầu web thường xuyên, bao gồm các yêu cầu cần thiết cho kinh doanh.
Cách vượt qua Cloudflare: các phương pháp thực tế
Xem xét các điều nói trên, hãy xem xét một số cách vượt qua bảo vệ Cloudflare.
Sử dụng proxy để vượt qua các kiểm tra Cloudflare
Các mạng proxy, đặc biệt là CyberYozh với cơ sở dữ liệu gồm hơn 50 triệu địa chỉ IP dân cư và di động trên toàn thế giới, giúp giảm rủi ro kích hoạt hệ thống phát hiện bot của Cloudflare bằng cách định tuyến các yêu cầu thông qua các địa chỉ IP có điểm tin tưởng cao và dữ liệu địa vị trí thực tế. Định tuyến lưu lượng thông qua proxy dân cư hoặc proxy di động làm cho các yêu cầu tự động hóa trông giống như các phiên người dùng hợp pháp. CyberYozh hỗ trợ xoay vòng IP động thông qua các giao thức HTTP và SOCKS5, đảm bảo Bot Score luôn cao ổn định trong suốt phiên scraping.
Tìm hiểu cách proxy giúp vượt qua CAPTCHA.
Sử dụng trình duyệt chống phát hiện và điện thoại đám mây
Các trình duyệt chống phát hiện và điện thoại đám mây cung cấp lớp bảo vệ tiếp theo, cung cấp các dấu vân tay trình duyệt và thiết bị độc đáo thực sự mà công cụ ML của Cloudflare coi là các thiết bị thực tế riêng biệt. Không giống như các trình duyệt headless tiêu chuẩn tiết lộ các dấu hiệu tự động hóa, các trình duyệt chống phát hiện làm cho mỗi phiên gần như không thể phân biệt được với người dùng thực. Kết hợp với proxy di động hoặc dân cư từ CyberYozh, mỗi phiên đại diện cho một danh tính đầy đủ và nhất quán, phù hợp với địa vị trí IP, dấu vân tay thiết bị và hành vi trình duyệt.
Tìm hiểu thêm về trình duyệt chống phát hiện và điện thoại đám mây trong các bài viết của CyberYozh.
Kết nối trực tiếp qua địa chỉ IP
Trong nhiều trường hợp, nếu biết địa chỉ IP của trang web đích, bạn có thể thiết lập kết nối trực tiếp với nó, bỏ qua tất cả các trung gian, bao gồm cơ sở hạ tầng Cloudflare. Phương pháp này yêu cầu tìm hiểu trước địa chỉ IP của trang web đích và có thể được thử trước khi sử dụng proxy hoặc công cụ chống phát hiện, mặc dù không phải lúc nào cũng hoạt động.
Giải pháp CAPTCHA tự động hóa
Vượt qua CAPTCHA của Cloudflare bằng cách sử dụng các dịch vụ CAPTCHA tự động hóa — là một tùy chọn cuối cùng, về cơ bản dựa trên phương pháp brute force, không giống như tất cả các cách tiếp cận khác hướng tới việc ngăn chặn các thử thách Cloudflare thay vì giải quyết chúng. Đọc thêm về dịch vụ giải quyết CAPTCHAđể hiểu khi nào phương pháp này áp dụng; tốt hơn là sử dụng nó như một tùy chọn dự phòng nếu CAPTCHA của Cloudflare vẫn được kích hoạt.
Cách tìm địa chỉ IP của một trang web
Có một số cách để tìm địa chỉ IP của trang web đích. Hãy xem xét chúng.
Các bản ghi DNS lịch sử cho tên miền, có sẵn thông qua các dịch vụ như SecurityTrails và ViewDNS, chứa địa chỉ IP của trang web cùng với các dữ liệu khác.
Tiêu đề email có thể chứa IP của người gửi nếu họ không sử dụng các dịch vụ như Google Workspace — có sẵn thông qua xem mã nguồn email và tìm kiếm các từ khóa Received: và Originating-IP:.
Chứng chỉ SSL/TLS có thể được tìm kiếm bằng các công cụ như Censys — địa chỉ IP của trang web nằm trực tiếp trong các chứng chỉ này.
Tìm kiếm thông qua Shodan — công cụ lập chỉ mục các thiết bị kết nối với Internet — có thể tiết lộ IP máy chủ của trang web thông qua nội dung trang duy nhất của nó.
Những phương pháp này không phổ quát, và trong nhiều trường hợp chúng sẽ không hoạt động vì IP đích có thể không có trong cơ sở dữ liệu, chứng chỉ và các nguồn khác. Tuy nhiên, nên thử chúng nếu cần thiết để xác định địa chỉ IP của trang web.
Tóm tắt: tại sao đôi khi cần phải vượt qua Cloudflare
Nếu bạn không thể vượt qua xác minh Cloudflare, bạn cần một dịch vụ giúp bạn vượt qua nó. Mặc dù cơ sở hạ tầng Cloudflare bảo vệ web khỏi những kẻ tấn công, nó cũng chặn nhiều tác nhân hợp pháp tham gia vào web scraping, multi-accounting, phân tích dữ liệu, tổng hợp giá vé và các nhiệm vụ khác yêu cầu các yêu cầu hàng loạt thường xuyên. Đó là lý do tại sao cần có mạng proxy và trình duyệt chống phát hiện ở đây — để xoay vòng các yêu cầu giữa các địa chỉ IP sạch và cung cấp các dấu vân tay thiết bị thực. Mặc dù có các phương pháp khác, việc sử dụng cơ sở hạ tầng proxy là cách tiếp cận đáng tin cậy nhất, cho phép doanh nghiệp tự động hóa hoạt động mà không tiết lộ dữ liệu và rủi ro bị chặn bởi Cloudflare. Do đó, đừng lãng phí thời gian — hãy khám phá danh mục CyberYozh và chọn proxy cho các mục đích của bạn.