Cài đặt proxy trong Crawl4AI
Crawl4AI — là một công cụ mã nguồn mở mạnh mẽ để quét web (web scraping), được thiết kế để trích xuất dữ liệu sạch từ các trang web, phù hợp cho việc huấn luyện các mô hình AI và LLM. Nó nhanh, linh hoạt và có khả năng vượt qua các lớp bảo vệ cơ bản của trang web như các hệ thống chống bot đơn giản. Đối với các lớp bảo vệ phức tạp hơn, bao gồm CAPTCHA, việc tích hợp với các dịch vụ bên thứ ba được khuyến nghị (xem Phần 4).
Tuy nhiên, khi quét trên quy mô lớn (ví dụ: 10.000 trang), địa chỉ IP cục bộ của bạn sẽ nhanh chóng bị chặn. Để tránh điều này và đảm bảo luồng dữ liệu liên tục cho các mô hình AI của bạn, một hạ tầng proxy đáng tin cậy là cần thiết. Trong hướng dẫn này, chúng ta sẽ tìm hiểu cách chọn loại proxy phù hợp từ CyberYozh App cho tác vụ của bạn và cách tích hợp chúng vào Crawl4AI.
🛑 Thông tin cực kỳ quan trọng về giao thức (HTTP vs SOCKS5): Thư viện Playwright (nền tảng của Crawl4AI) không hỗ trợ proxy SOCKS5 có xác thực (login:password). Vì tất cả proxy trong CyberYozh App đều hoạt động chỉ với xác thực để bảo mật, nên để làm việc với Crawl4AI, bạn cần sử dụng giao thức HTTP. Nó hỗ trợ đầy đủ việc xác thực và đảm bảo hoạt động ổn định.
Các đặc điểm chính của việc tích hợp: Proxy là một mô-đun riêng biệt (proxy_module.py) để đảm bảo tính mô-đun. Dữ liệu được lưu trữ trong các tệp văn bản (theo loại: dân cư, di động, trung tâm dữ liệu). Việc chuyển đổi loại/giao thức chỉ mất một hoặc hai dòng trong kịch bản chính.
Phần 1. Chọn Proxy: Loại nào phù hợp cho tập dữ liệu của bạn?
Crawl4AI rất đa năng, nhưng hiệu quả phụ thuộc vào "nhiên liệu" — đó là nhóm địa chỉ IP. Trong CyberYozh App, có sẵn nhiều loại proxy khác nhau, mỗi loại được tối ưu hóa cho các tình huống quét web cụ thể. Việc lựa chọn phụ thuộc vào mức độ bảo vệ của trang web, khối lượng dữ liệu và nhu cầu xoay vòng IP. Tất cả các loại đều hỗ trợ cả HTTP và SOCKS5.
- Proxy Dân cư Xoay vòng (Residential Rotating) — Lựa chọn số 1 cho quét web hàng loạt
- Bản chất: Nhóm hàng triệu địa chỉ IP nhà riêng thực tế. Xoay vòng tự động: IP mới qua liên kết hoặc yêu cầu API.
- Lý tưởng cho Crawl4AI: Tập dữ liệu lớn từ các sàn thương mại điện tử (Amazon, Wildberries), công cụ tìm kiếm (Google, Yandex).
- Tại sao: Độ tin cậy cao, giảm thiểu việc bị chặn. Hỗ trợ 3 loại phiên (IP ngẫu nhiên, Ngắn hạn, Dài hạn lên đến 6 giờ).
- Proxy Dân cư Tĩnh (Residential Static / ISP)
- Bản chất: Các IP nhà riêng cố định trong thời hạn thuê.
- Lý tưởng cho Crawl4AI: Các trang web yêu cầu đăng nhập (tài khoản cá nhân).
- Tại sao: Tính ổn định của phiên làm việc.
- Cổng Di động Riêng biệt (Mobile Dedicated)
- Bản chất: Modem riêng với SIM thật, được dành riêng cho cá nhân bạn.
- Lý tưởng cho Crawl4AI: Các tác vụ phức tạp, trang web có bảo vệ chống bot nghiêm ngặt, mô phỏng hành vi của người dùng thực trên thiết bị di động.
- Tại sao: Độ tin cậy tối đa từ phía các trang web. Được khuyên dùng cho các trường hợp khó khăn nhất.
- Proxy Di động Chia sẻ (Mobile Shared)
- Bản chất: IP từ mạng 4G/5G, kênh chia sẻ trong chế độ riêng tư.
- Lý tưởng cho Crawl4AI: Mạng xã hội (Instagram, TikTok) hoặc các trang web có bảo vệ (Cloudflare).
- Tại sao: Độ tin cậy cao đối với lưu lượng di động.
- Proxy Trung tâm dữ liệu Riêng biệt (Datacenter)
- Bản chất: IP máy chủ, nhanh và rẻ.
- Lý tưởng cho Crawl4AI: Các nguồn mở không có lớp bảo vệ.
- Tại sao: Tốc độ tối đa.
Lời khuyên tích hợp: Đối với cách tiếp cận hỗn hợp, hãy kết hợp các loại proxy.
Phần 2. Chuẩn bị dữ liệu và cài đặt
Chuẩn bị dữ liệu từ CyberYozh App:
Sau khi mua proxy, hãy sao chép dữ liệu:
- Host (IP): 51.77.190.247
- Port: 5959
- Login: user123
- Password: pass123
Định dạng chuỗi kết nối: Crawl4AI (giống như thư viện Playwright bên dưới) nhận proxy ở định dạng chuỗi duy nhất: http://login:password@ip:port
Ví dụ: http://user123:pass123@51.77.190.247:5959
Quản lý Proxy Dân cư Xoay vòng
Đối với Proxy Dân cư Xoay vòng trong CyberYozh App, bạn có thể thiết lập phiên linh hoạt ngay thông qua tên đăng nhập (username). Điều này cực kỳ quan trọng đối với logic của trình quét.
Thông tin đăng nhập có thể được tạo trong tài khoản cá nhân bằng cách nhấn nút “Tạo thông tin đăng nhập” trong thẻ gói dịch vụ. Các định dạng đầu ra có sẵn: IP:PORT:USERNAME:PASSWORD hoặc liên kết cho cURL.
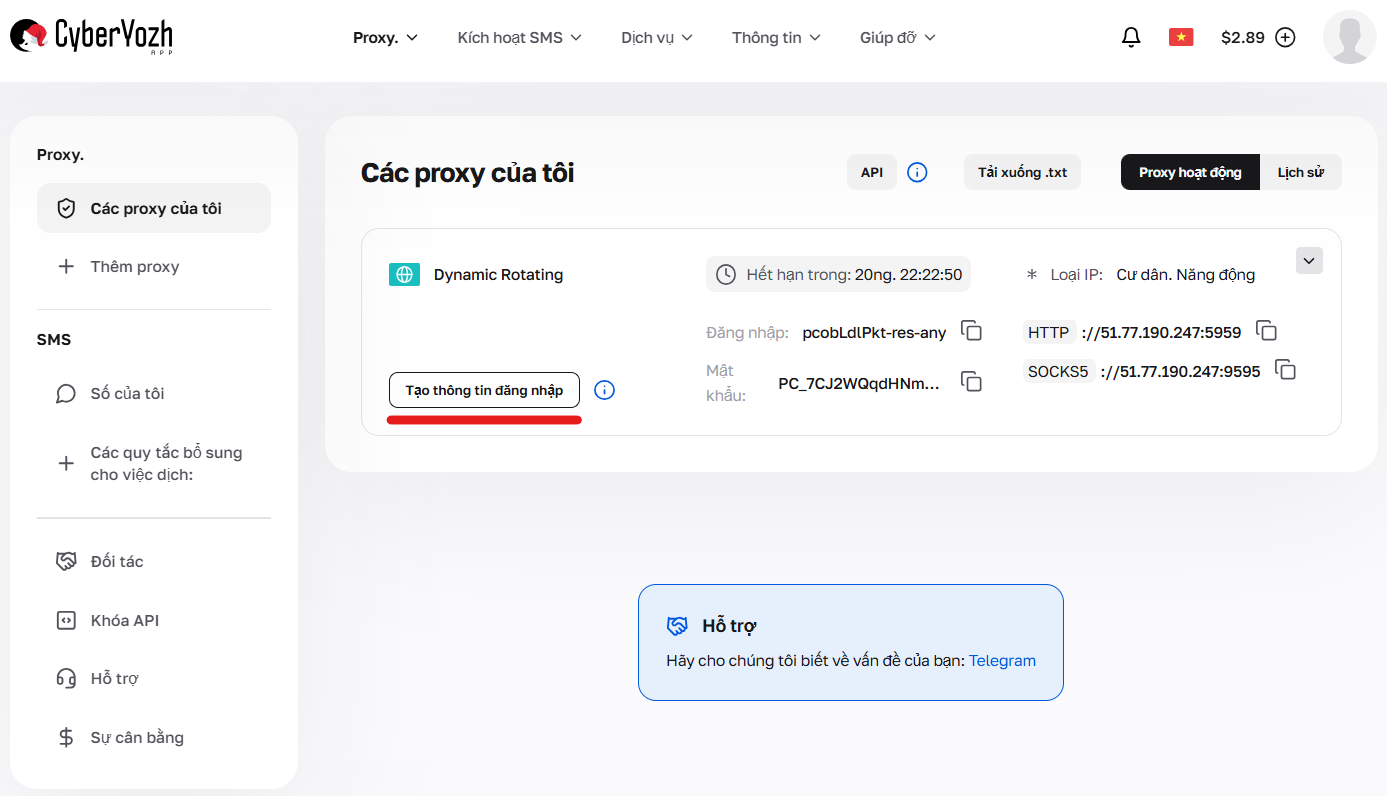
Hình 1. Chuyển đến giao diện tạo cấu hình và tham số kết nối (trình tạo thông tin đăng nhập).
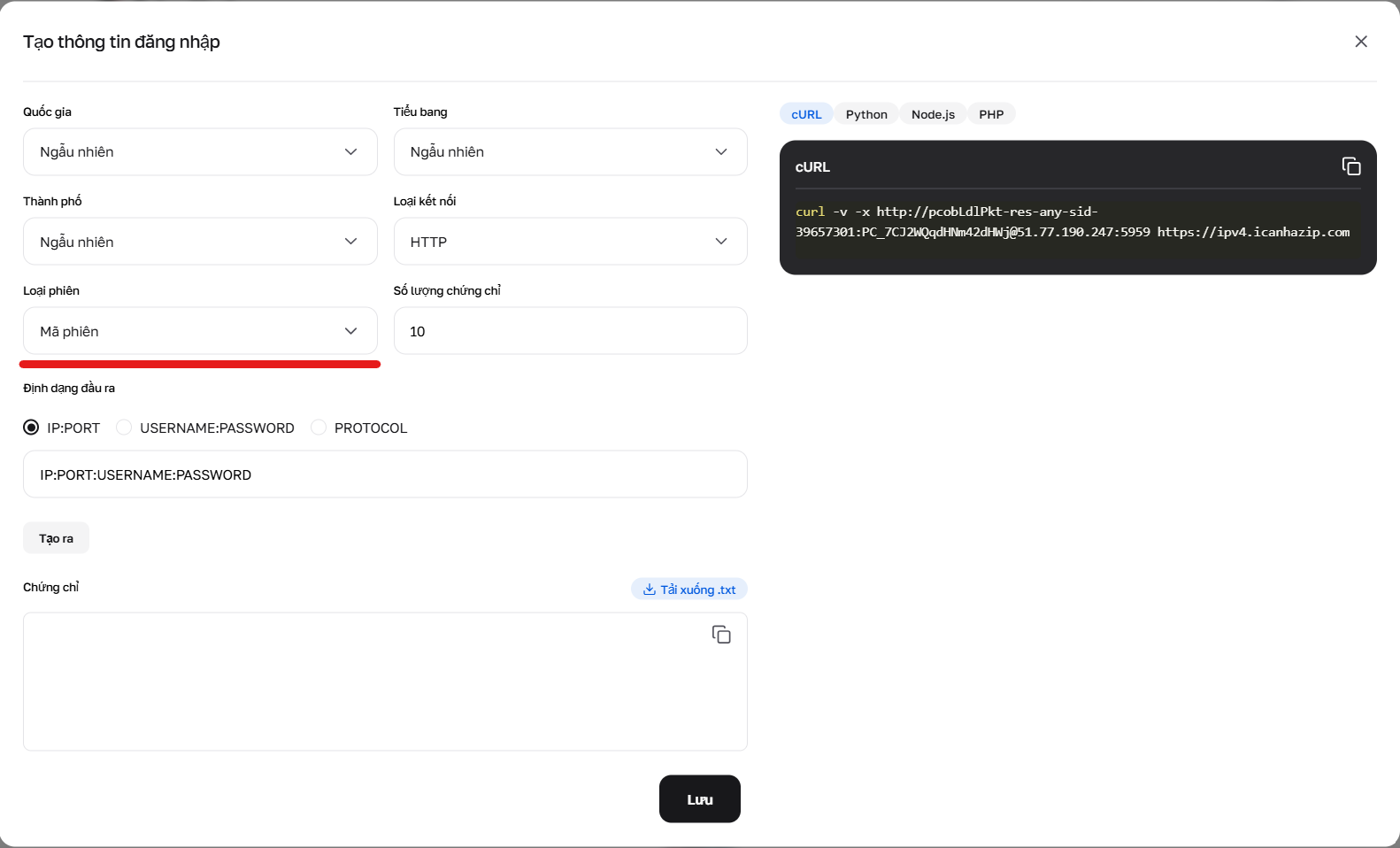
Hình 2. Sử dụng trình tạo để thiết lập tham số sid, chịu trách nhiệm tạo các phiên duy nhất mới.
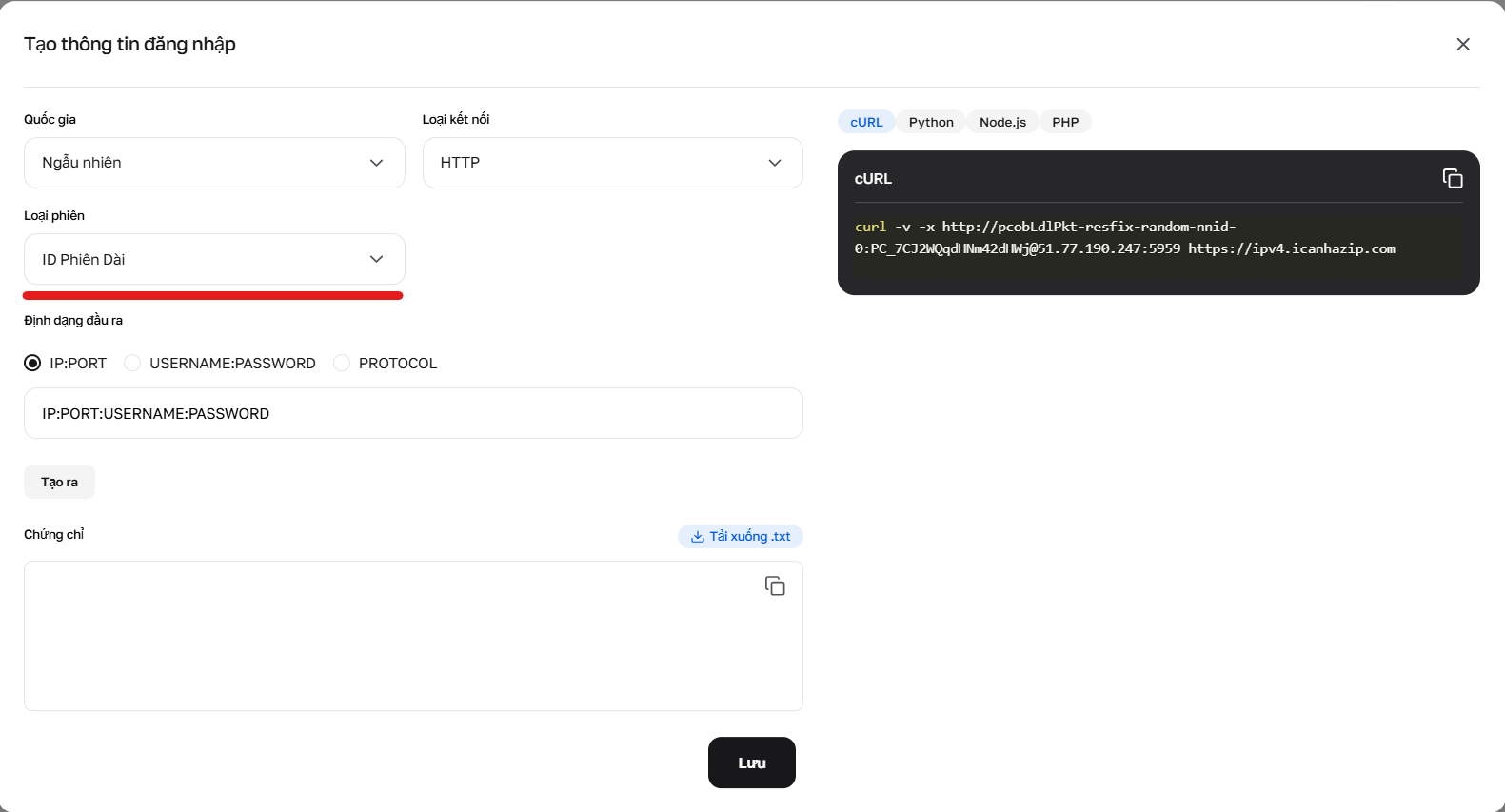
Hình 3. Thiết lập các tham số để tạo thông tin đăng nhập sử dụng các phiên dài (Sticky).
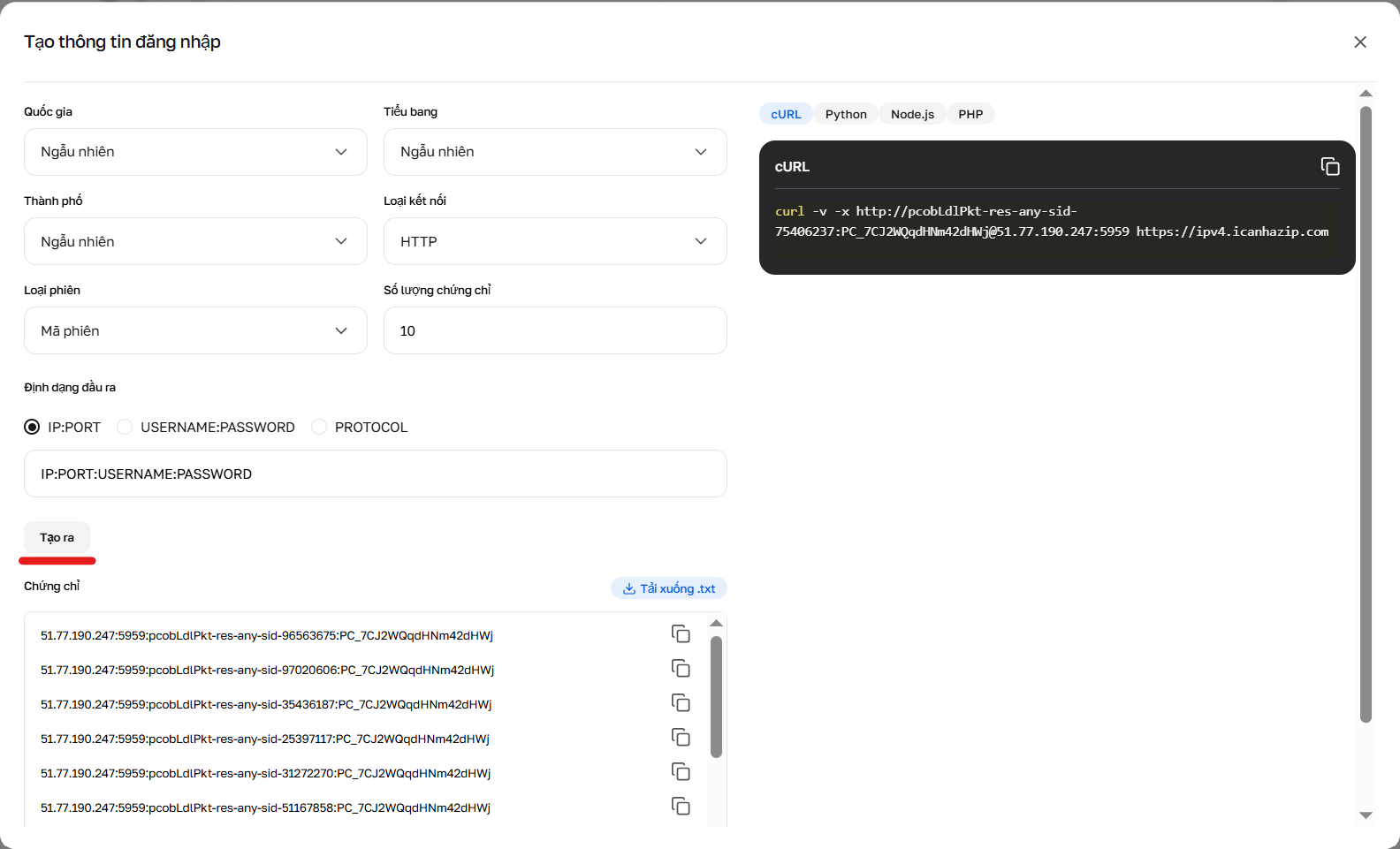
Hình 4. Kết quả làm việc của trình tạo thông tin đăng nhập.
Các loại phiên và cách khai báo:
1. IP ngẫu nhiên (Random IP) — mỗi yêu cầu một IP mới Sử dụng tiền tố -res-any. Ví dụ đăng nhập: user-res-any Khi cần: Quét web thông thường, nơi không cần giữ trạng thái giữa các trang.
2. Phiên ngắn (tối đa 1 phút) Cho phép giữ IP trong thời gian ngắn (ví dụ: để giải captcha và tải trang). Sử dụng tiền tố -sid-RANDOMNUMBER.
Định dạng: user-res-any-sid-47551677 (trong đó 47551677 — là bất kỳ số ngẫu nhiên nào do bạn tạo ra).
Vị trí địa lý: Trong các phiên ngắn, bạn có thể chọn Quốc gia, Khu vực và Thành phố (ví dụ: -res_sc-us_georgia_macon-sid-54683597).
3. Phiên dính dài hạn (tối đa 6 giờ) Đây là Sticky-session, giữ một IP lên đến 6 giờ. Lý tưởng cho việc phân tích sâu một trang web.
Cách lấy: Cách A (Đơn giản): Tạo chuỗi có sẵn với "Phiên dài" trong trình tạo thông tin đăng nhập tại tài khoản cá nhân. Cách B (Nâng cao/API): Cần thực hiện 2 bước. Gửi yêu cầu cURL với tiền tố -resfix- (ví dụ: user-resfix-us-nnid-0). Trong tiêu đề phản hồi X-NN-LLS lấy token (ví dụ: 9d016e26...). Thay token này vào vị trí số 0 trong tên đăng nhập: user-resfix-us-nnid-9d016e26....
Quản lý proxy di động trong tài khoản cá nhân
Làm việc với proxy di động có một đặc điểm quan trọng: để đổi IP, hãy sử dụng liên kết API. Hãy chắc chắn tìm thấy nó trong thẻ gói dịch vụ đã mua — đây chính là URL cần chèn vào phần mềm hoặc kịch bản của bạn để thiết lập xoay vòng tự động.
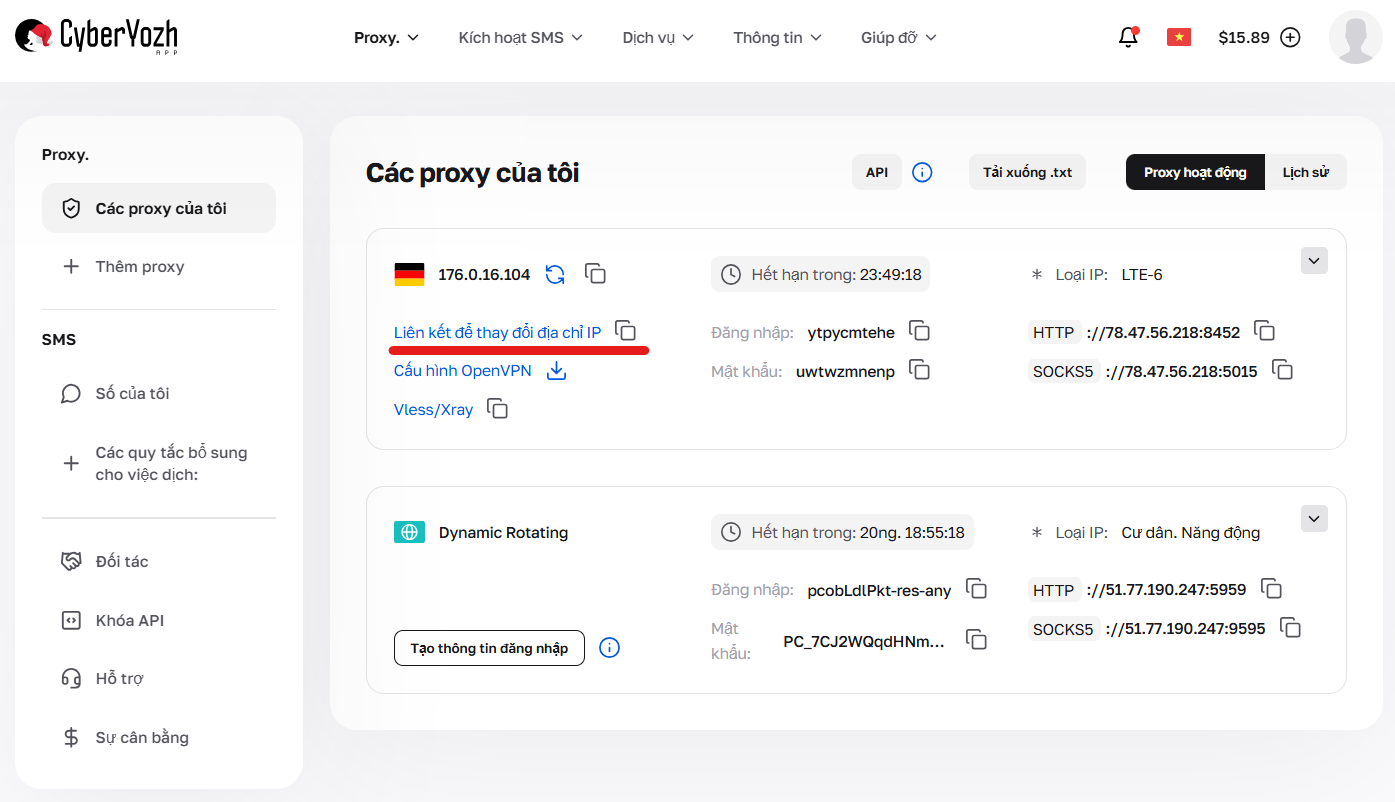
Hình 5. Vị trí liên kết để xoay vòng tự động.
Ngoài ra, CyberYozh App còn cung cấp chế độ thủ công. Nếu bạn cần đổi địa chỉ IP ngay lập tức mà không cần dùng kịch bản, chỉ cần nhấn nút đổi IP trong bảng điều khiển — địa chỉ sẽ được cập nhật tức thì.
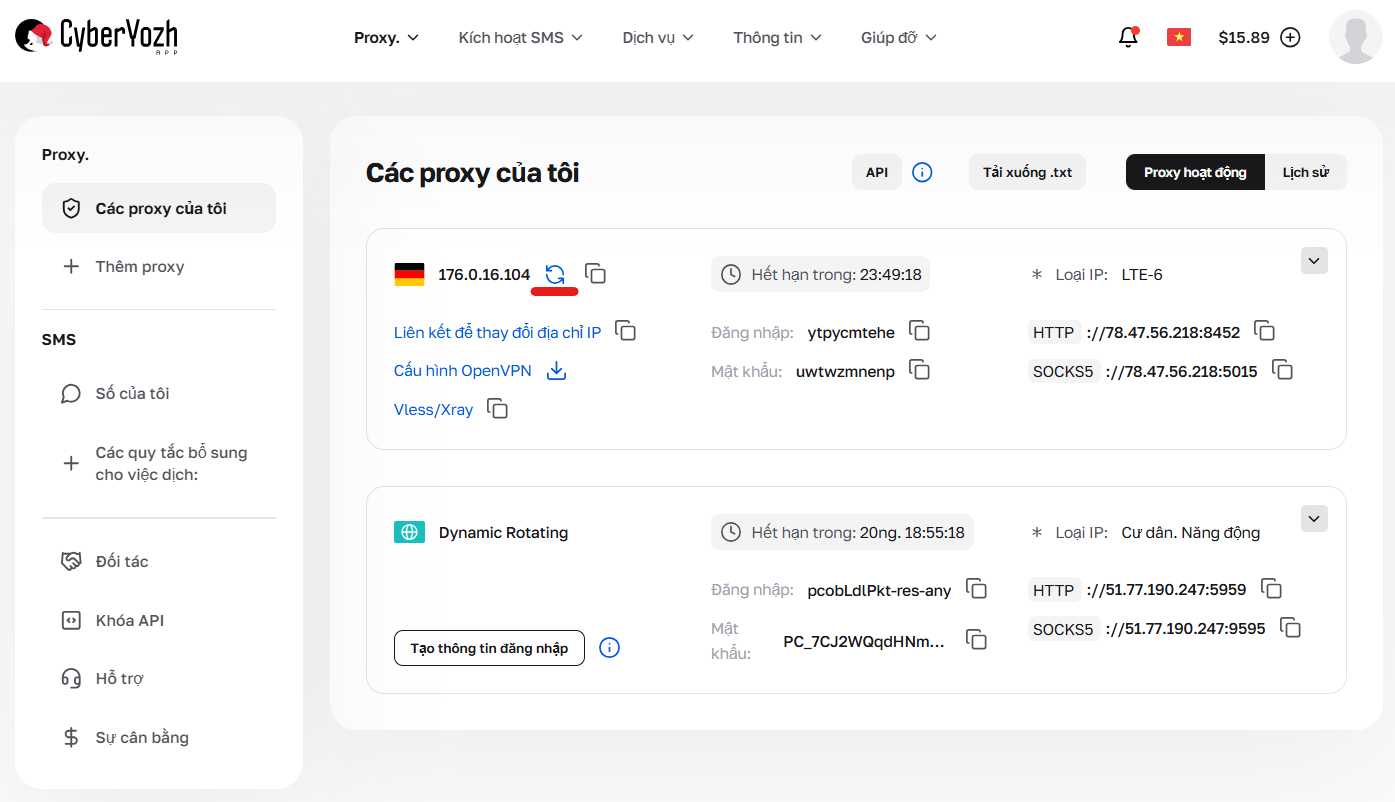
Hình 6. Nút để cưỡng bức đổi IP thủ công.
Tạo các tệp trong thư mục dự án:
proxies_residential.txt:
user123:pass123@51.77.190.247:5959 Thêm nhiều proxy hơn để xoay vòng.
proxies_mobile.txt và proxies_datacenter.txt tương tự. * Định dạng: login:password@host:port cho auth (chỉ với HTTP).
Cài đặt:
pip install crawl4ai playwright
playwright install
Kiểm tra cài đặt: python -m crawl4ai --version. Sử dụng venv nếu cần thiết.
Phần 3. Tích hợp proxy vào Crawl4AI (Python) như một mô-đun riêng biệt
Mô-đun proxy_module.py tải proxy từ các tệp, thêm giao thức ("http" hoặc "socks5") và hỗ trợ xoay vòng.
Bước 1. Mô-đun proxy (proxy_module.py):
import random
import os
class ProxyManager:
def __init__(self, proxy_type="residential", protocol="http", rotate=True):
"""
Khởi tạo trình quản lý proxy.
:param proxy_type: Loại ('residential', 'mobile', 'datacenter')
:param protocol: Giao thức ('http' hoặc 'socks5') — socks5 chỉ khi không có auth!
:param rotate: Bật/tắt xoay vòng
"""
self.proxy_type = proxy_type.lower()
self.protocol = protocol.lower()
self.rotate = rotate
self.proxies = self._load_proxies() # Tải từ tệp
if self.protocol == "socks5" and self.proxies and '@' in self.proxies[0]: # Kiểm tra auth
raise ValueError("SOCKS5 không hỗ trợ xác thực trong Playwright! Hãy xóa login:password khỏi tệp.")
self.current_proxy = None
def _load_proxies(self):
"""Tải proxy từ tệp."""
file_map = {
"residential": "proxies_residential.txt",
"mobile": "proxies_mobile.txt",
"datacenter": "proxies_datacenter.txt"
}
file_name = file_map.get(self.proxy_type)
if not file_name:
raise ValueError(f"Loại không xác định: {self.proxy_type.")
file_path = os.path.join(os.path.dirname(__file__), file_name)
if not os.path.exists(file_path):
raise FileNotFoundError(f"Không tìm thấy tệp {file_name.")
with open(file_path, 'r') as f:
lines = f.read().strip().splitlines()
# Thêm giao thức: protocol://line (line = user:pass@host:port hoặc host:port)
proxies = [f"{self.protocol://{line.strip()" for line in lines if line.strip()]
if not proxies:
raise ValueError(f"Tệp {file_name trống.")
return proxies
def get_proxy(self):
"""Trả về proxy."""
if not self.proxies:
raise ValueError("Không có proxy!")
if self.rotate:
self.current_proxy = random.choice(self.proxies)
else:
self.current_proxy = self.proxies[0]
return self.current_proxy
def get_proxy_config(self):
"""Trả về ProxyConfig cho Crawl4AI."""
if not self.current_proxy:
self.get_proxy()
# Phân tách: protocol://user:pass@host:port hoặc protocol://host:port
if '@' in self.current_proxy:
parts = self.current_proxy.split('@')
auth = parts[0].split('//')[1] # user:pass
host_port = parts[1] # host:port
user, password = auth.split(':')
else:
host_port = self.current_proxy.split('//')[1] # host:port cho no-auth
user, password = None, None
from crawl4ai.async_configs import ProxyConfig
return ProxyConfig(
server=f"{self.protocol://{host_port",
username=user,
password=password
)
def add_proxy(self, proxy_url):
self.proxies.append(proxy_url)
Bước 2. Kịch bản trình quét (scraper.py):
import asyncio
from crawl4ai import AsyncWebCrawler
from crawl4ai.async_configs import BrowserConfig
from proxy_module import ProxyManager
# Chuyển đổi loại (residential, mobile, datacenter)
PROXY_TYPE = "residential"
# Chuyển đổi giao thức (http hoặc socks5 — socks5 chỉ khi không có auth!)
PROXY_PROTOCOL = "http" # Khuyên dùng cho auth; đối với SOCKS5 hãy xóa login:password khỏi tệp
# Khởi tạo trình quản lý
proxy_manager = ProxyManager(proxy_type=PROXY_TYPE, protocol=PROXY_PROTOCOL, rotate=True)
async def main():
try:
proxy_config = proxy_manager.get_proxy_config()
browser_config = BrowserConfig(proxy_config=proxy_config)
async with AsyncWebCrawler(verbose=True, config=browser_config) as crawler:
current_proxy = proxy_manager.get_proxy()
print(f"🚀 Đang khởi chạy qua {PROXY_PROTOCOL.upper() proxy...")
print(f"Proxy: {current_proxy")
result = await crawler.arun(
url="https://ipinfo.io/json",
bypass_cache=True
)
if result.success:
print("\n✅ Thành công! Phản hồi:")
print(result.markdown)
else:
print(f"\n❌ Lỗi: {result.error_message")
except Exception as e:
print(f"❌ Lỗi: {str(e)")
if __name__ == "__main__":
asyncio.run(main())
Bước 3. Khởi chạy:
python scraper.py
- Đối với SOCKS5: Thiết lập PROXY_PROTOCOL = "socks5" và xóa auth khỏi các tệp (chỉ để lại host:port). Nếu cần auth — hãy sử dụng HTTP proxy.
Phần 4. Các tình huống nâng cao và giải quyết vấn đề
Xoay vòng tự động (cho proxy dân cư xoay vòng và di động):
Không cần thêm mã — cổng CyberYozh App sẽ tự xoay vòng IP. Chỉ cần gọi crawler.arun trong một vòng lặp:
for url in urls_list:
proxy_config = proxy_manager.get_proxy_config() # Cấu hình mới để xoay vòng
browser_config = BrowserConfig(proxy_config=proxy_config)
# Khởi tạo lại crawler với config mới nếu cần
result = await crawler.arun(url=url, bypass_cache=True)
Xoay vòng thủ công cho các IP tĩnh (dân cư/trung tâm dữ liệu):
Thêm vài dòng vào tệp proxies_residential.txt hoặc proxies_datacenter.txt và sử dụng rotate=True. Hoặc sử dụng việc đổi IP qua liên kết hoặc yêu cầu API.
Quét hàng loạt với khoảng nghỉ:
Thêm các khoảng trễ để mô phỏng hành vi của con người:
import time
time.sleep(random.uniform(1, 5)) # Nghỉ 1-5 giây trước khi gửi yêu cầu
💡 Lời khuyên: một số trang web có thể sử dụng cơ chế kiểm tra dựa trên CAPTCHA để ngăn chặn truy cập tự động. Nếu quy trình làm việc của bạn gặp phải những vấn đề như vậy, bạn có thể tích hợp dịch vụ xử lý CAPTCHA bên thứ ba, chẳng hạn như CapSolver. Nó hỗ trợ reCAPTCHA v2/v3, Cloudflare Turnstile, Challenge, AWS WAF và các loại khác. Hãy đảm bảo rằng việc sử dụng của bạn tuân thủ các điều khoản dịch vụ của trang web mục tiêu và luật pháp hiện hành.
Giải quyết vấn đề:
- Lỗi kết nối: Kiểm tra định dạng trong các tệp (login:password@host:port). Kiểm tra proxy trong trình duyệt.
- Bị chặn mặc dù đã dùng proxy: Tăng thời gian nghỉ hoặc đổi loại proxy (sang di động cho các trang web khó). Thêm chế độ tàng hình (stealth mode) trong Crawl4AI: browser_type="undetected" trong BrowserConfig.
- Lỗi Playwright: Đảm bảo rằng playwright install đã được thực hiện. Nếu headless=False, trình duyệt sẽ mở công khai để gỡ lỗi.
- Lỗi xác thực SOCKS5: Playwright không hỗ trợ — hãy sử dụng proxy HTTP.
- Ngoại lệ Asyncio: Có thể bỏ qua; đây là đặc thù của Windows, không ảnh hưởng.
- Ghi nhật ký: Bật verbose=True trong Crawl4AI để xem nhật ký chi tiết.
Kết luận
Crawl4AI + proxy từ CyberYozh App — là bộ đôi lý tưởng để thu thập dữ liệu mà không bị chặn. Hãy chọn:
- Proxy Dân cư Xoay vòng cho các tập dữ liệu lớn (Amazon/Google).
- Proxy Di động Chia sẻ cho mạng xã hội và các trang web có bảo vệ.
- Proxy Dân cư Tĩnh cho các tác vụ cần giữ phiên làm việc.
- Proxy Trung tâm dữ liệu Tĩnh cho việc thu thập dữ liệu đơn giản và nhanh chóng.
Hãy truy cập vào danh mục của CyberYozh App, chọn các proxy phù hợp, thiết lập Crawl4AI và mở rộng quy mô quét AI của bạn.
Tài liệu bổ sung: Crawl4AI GitHub