Configuração do proxy no Crawl4AI
Crawl4AI — é uma poderosa ferramenta open-source de web scraping, projetada para extrair dados limpos de páginas web, ideais para o treinamento de modelos de IA e LLM. É rápido, flexível e capaz de contornar proteções básicas de sites, como sistemas anti-bot simples. Para proteções mais complexas, incluindo CAPTCHA, recomenda-se a integração com serviços de terceiros (veja a Parte 4).
No entanto, em scrapings de larga escala (por exemplo, 10.000 páginas), seu endereço IP local será rapidamente bloqueado. Para evitar isso e garantir um fluxo contínuo de dados para seus modelos de IA, é necessária uma infraestrutura de proxy confiável. Neste guia, vamos analisar como escolher o tipo de proxy adequado do CyberYozh App para sua tarefa e como integrá-los ao Crawl4AI.
🛑 Informação crucial sobre protocolos (HTTP vs SOCKS5): A biblioteca Playwright (na qual o Crawl4AI se baseia) não suporta proxies SOCKS5 com autenticação (login:password). Como todos os proxies no CyberYozh App funcionam apenas com autenticação por motivos de segurança, para trabalhar com o Crawl4AI você deve utilizar o protocolo HTTP. Ele suporta totalmente a autenticação e garante uma operação estável.
Principais características da integração: Proxy como um módulo separado (proxy_module.py) para modularidade. Os dados são armazenados em arquivos de texto (por tipo: residenciais, móveis, datacenter). A troca de tipo/protocolo é feita em uma ou duas linhas no script principal.
Parte 1. Escolha do Proxy: Qual tipo é adequado para o seu conjunto de dados?
O Crawl4AI é versátil, mas sua eficácia depende do "combustível" — o pool de endereços IP. No CyberYozh App, estão disponíveis diferentes tipos de proxies, cada um otimizado para cenários específicos de scraping. A escolha depende do nível de proteção do site, do volume de dados e da necessidade de rotação. Todos os tipos suportam tanto HTTP quanto SOCKS5.
- Residenciais Rotativos (Residential Rotating) — Escolha nº 1 para scraping em massa
- Essência: Um pool de milhões de endereços IP domésticos reais. Rotação automática: novo IP via link ou solicitação de API.
- Ideal para Crawl4AI: Grandes conjuntos de dados de marketplaces (Amazon, Wildberries), motores de busca (Google, Yahoo).
- Por que: Alta confiança (trust), minimiza bloqueios. Suporta 3 tipos de sessões (IP Aleatório, Curta, Longa de até 6 horas).
- Residenciais Estáticos (Residential Static / ISP)
- Essência: IPs domésticos fixos pelo período de aluguel.
- Ideal para Crawl4AI: Sites com autenticação (áreas logadas).
- Por que: Estabilidade das sessões.
- Portas Móveis Dedicadas (Mobile Dedicated)
- Essência: Um modem privado com um chip SIM real, dedicado pessoalmente a você.
- Ideal para Crawl4AI: Tarefas complexas, sites com proteção anti-bot rigorosa, emulação do comportamento de um usuário real de dispositivo móvel.
- Por que: Máxima confiança por parte dos sites. Recomendado para os casos mais difíceis.
- Proxies Móveis Compartilhados (Mobile Shared)
- Essência: IP de 4G/5G, canal compartilhado em modo privado.
- Ideal para Crawl4AI: Redes sociais (Instagram, TikTok) ou sites com proteção (Cloudflare).
- Por que: Alta confiança para tráfego móvel.
- Proxies Datacenter Dedicados (Datacenter)
- Essência: IPs de servidor, rápidos e econômicos.
- Ideal para Crawl4AI: Fontes abertas sem proteção pesada.
- Por que: Velocidade máxima.
Dica de integração: Para uma abordagem híbrida, combine os tipos.
Parte 2. Preparação dos Dados e Instalação
Prepare os dados do CyberYozh App:
Após a compra do proxy, copie os dados:
- Host (IP): 51.77.190.247
- Porta: 5959
- Login: user123
- Senha: pass123
Formato da string de conexão: O Crawl4AI (assim como a biblioteca Playwright subjacente) aceita proxies no formato de uma única string: http://login:senha@ip:porta
Exemplo: http://user123:pass123@51.77.190.247:5959
Gerenciamento de Proxies Residenciais Rotativos
Para os Proxies Residenciais Rotativos no CyberYozh App, está disponível uma configuração flexível de sessão diretamente através do login (username). Isso é crucial para a lógica do seu scraper.
As credenciais podem ser geradas no painel de controle, clicando no botão “Gerar credenciais” no card do pacote. Formatos de saída disponíveis: IP:PORT:USERNAME:PASSWORD ou link para cURL.
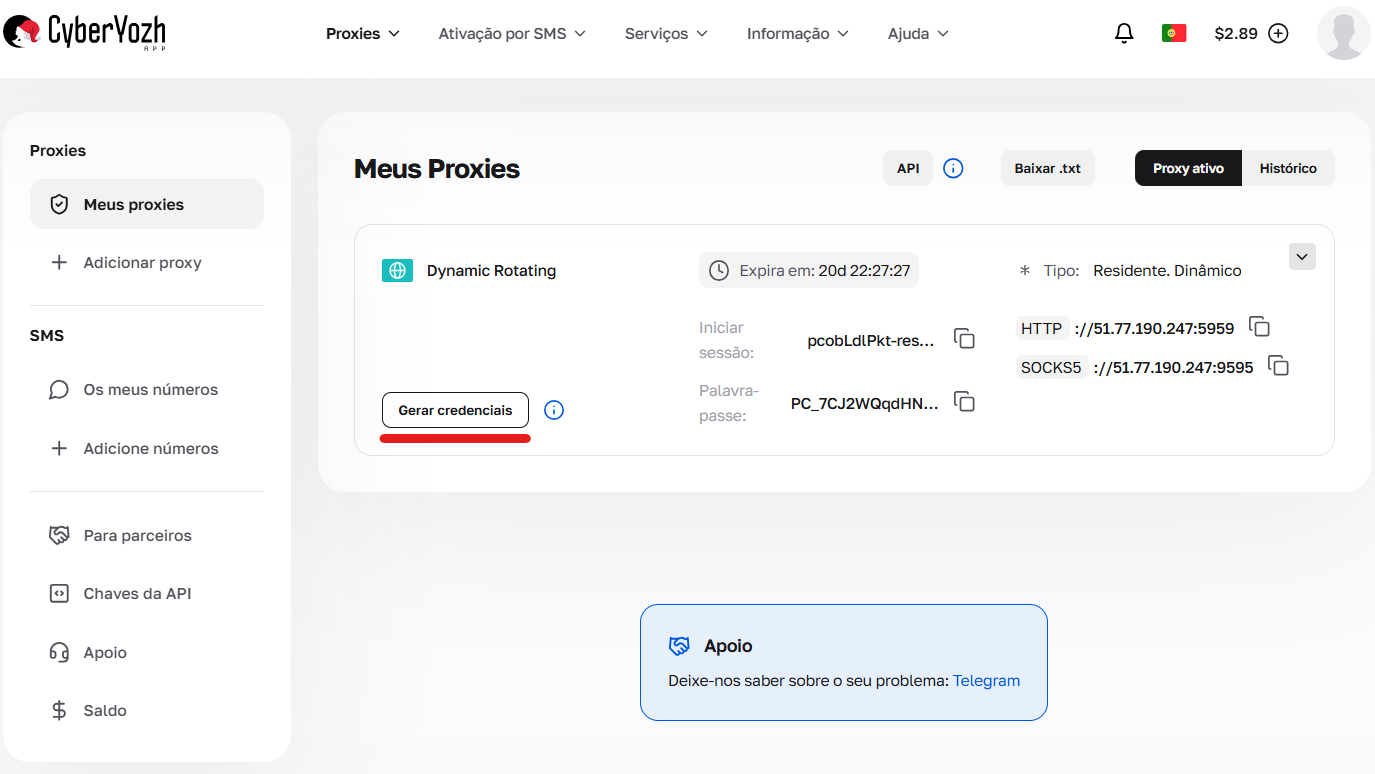
Fig. 1. Transição para a interface de criação de configurações e parâmetros de conexão (gerador de credenciais).
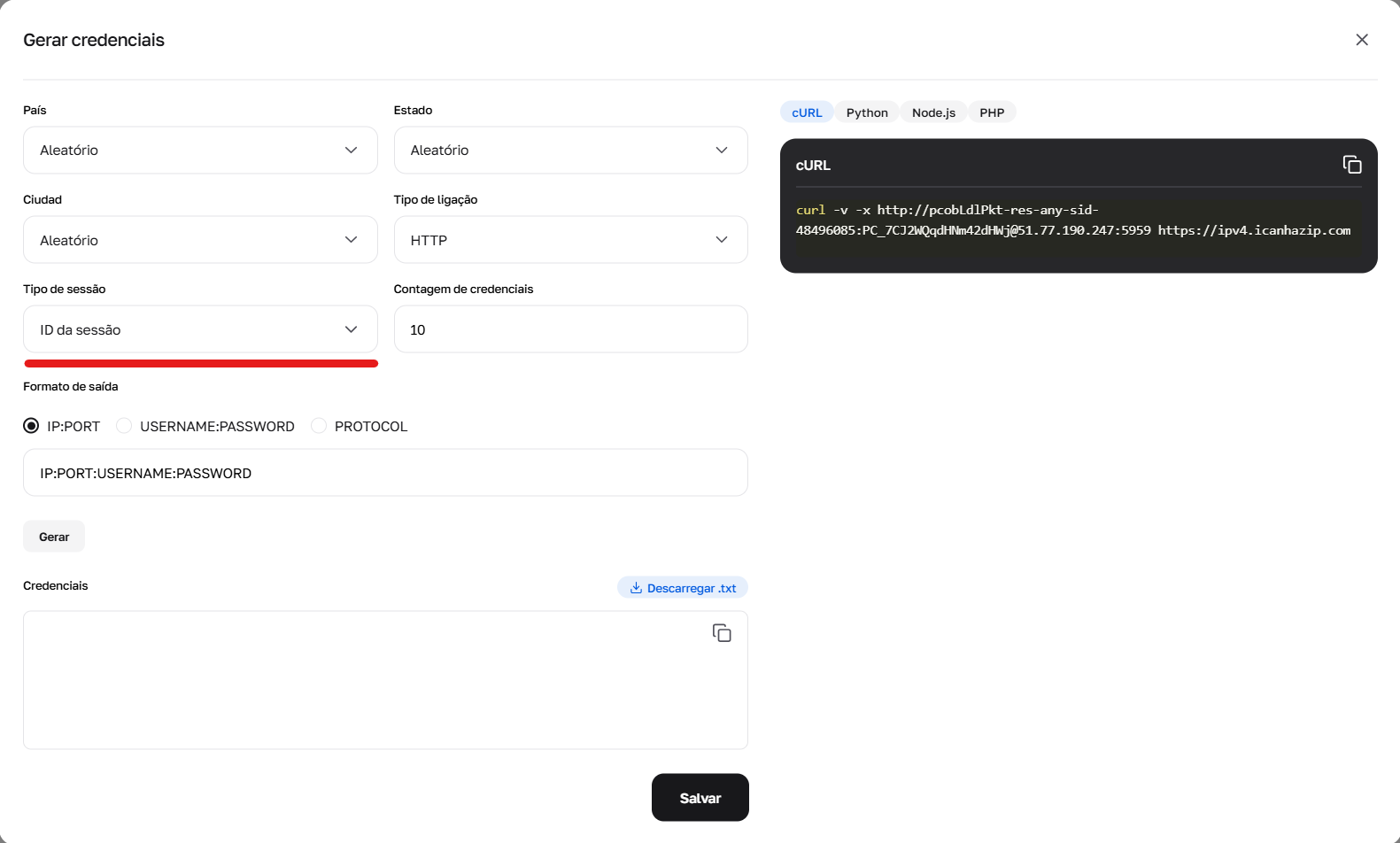
Fig. 2. Uso do gerador para configurar o parâmetro sid, responsável pela criação de novas sessões únicas.
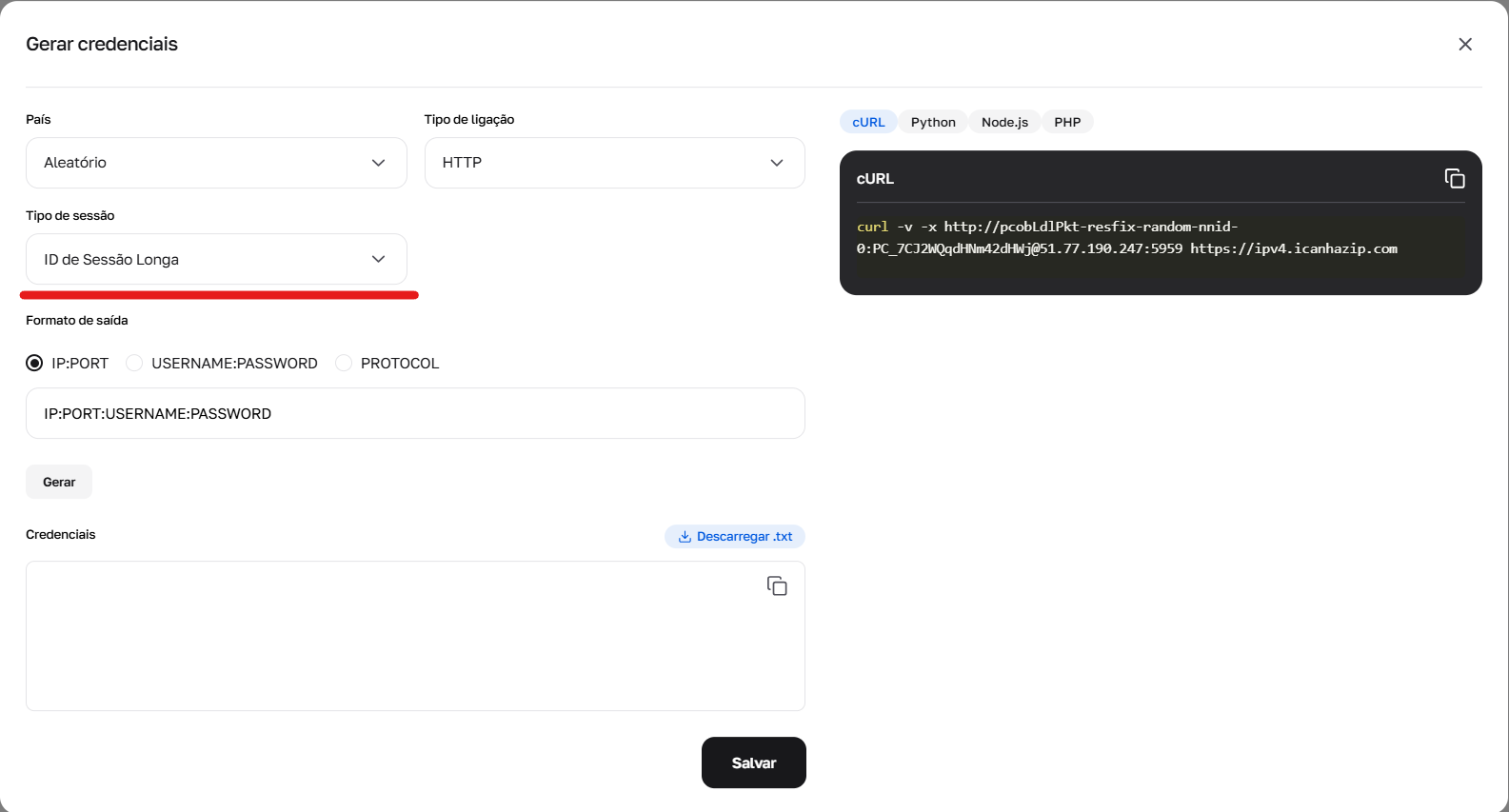
Fig. 3. Configuração de parâmetros para formação de credenciais usando sessões longas (Sticky).
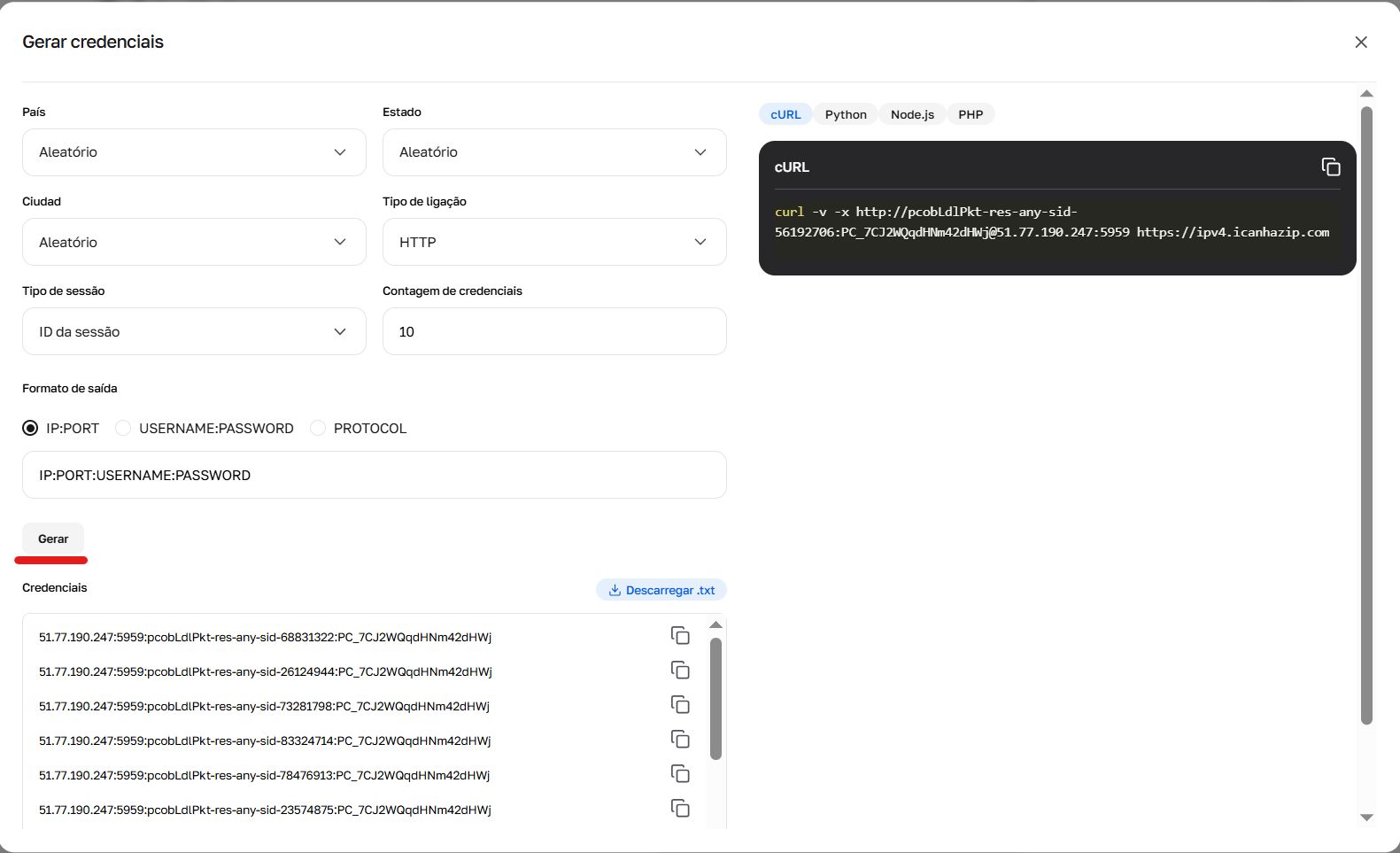
Fig. 4. Resultado da operação do gerador de credenciais.
Tipos de sessões e como defini-las:
1. IP Aleatório (Random IP) — um novo IP para cada requisição Utilize o prefixo -res-any. Exemplo de login: user-res-any Quando necessário: Scraping comum, onde não é preciso manter o estado entre as páginas.
2. Sessão Curta (até 1 minuto) Permite manter o IP por um curto período (ex: passar um captcha e carregar a página). Utilize o prefixo -sid-NUMEROALEATORIO.
Formato: user-res-any-sid-47551677 (onde 47551677 é qualquer número aleatório gerado por você).
Geo: Em sessões curtas, é possível escolher País, Região e Cidade (ex: -res_sc-us_georgia_macon-sid-54683597).
3. Sessão Longa Persistente (até 6 horas) Esta é a sessão Sticky, que mantém o mesmo IP por até 6 horas. Ideal para parsing profundo de um único site.
Como obter: Opção A (Simples): Gerar uma string pronta com "Sessão Longa" no gerador de credenciais no seu painel. Opção B (Avançado/API): É necessário realizar 2 passos. Fazer uma requisição cURL com o prefixo -resfix- (ex: user-resfix-us-nnid-0). No cabeçalho da resposta X-NN-LLS obter um token (ex: 9d016e26...). Substituir este token no lugar do 0 no login: user-resfix-us-nnid-9d016e26....
Gerenciamento de proxies móveis no painel de controle
O trabalho com proxies móveis tem uma característica importante: para a troca de IP, utiliza-se um link de API. Certifique-se de encontrá-lo no card do pacote adquirido — é este o URL que deve ser inserido no seu software ou script para configurar a rotação automática.
Fig. 5. Localização do link para rotação automática.
Além disso, no CyberYozh App existe o modo manual. Se você precisar trocar o endereço IP agora mesmo, sem recorrer a scripts, basta clicar no botão de troca de IP no painel de controle — o endereço será atualizado instantaneamente.
Fig. 6. Botão para troca manual forçada.
Crie os arquivos no diretório do projeto:
proxies_residential.txt:
user123:pass123@51.77.190.247:5959 Adicione mais proxies para rotação.
proxies_mobile.txt e proxies_datacenter.txt da mesma forma. * Formato: login:senha@host:porta para auth (apenas com HTTP).
Instalação:
pip install crawl4ai playwright
playwright install
Verifique a instalação: python -m crawl4ai --version. Use venv, se necessário.
Parte 3. Integração de Proxy no Crawl4AI (Python) como um Módulo Separado
O módulo proxy_module.py carrega os proxies dos arquivos, adiciona o protocolo ("http" ou "socks5") e suporta rotação.
Passo 1. Módulo de Proxy (proxy_module.py):
import random
import os
class ProxyManager:
def __init__(self, proxy_type="residential", protocol="http", rotate=True):
"""
Inicialização do gerenciador de proxy.
:param proxy_type: Tipo ('residential', 'mobile', 'datacenter')
:param protocol: Protocolo ('http' ou 'socks5') — socks5 apenas sem auth!
:param rotate: Liga/desliga rotação
"""
self.proxy_type = proxy_type.lower()
self.protocol = protocol.lower()
self.rotate = rotate
self.proxies = self._load_proxies() # Carrega do arquivo
if self.protocol == "socks5" and self.proxies and '@' in self.proxies[0]: # Verificação de auth
raise ValueError("O SOCKS5 não suporta autenticação no Playwright! Remova login:password do arquivo.")
self.current_proxy = None
def _load_proxies(self):
"""Carrega proxies do arquivo."""
file_map = {
"residential": "proxies_residential.txt",
"mobile": "proxies_mobile.txt",
"datacenter": "proxies_datacenter.txt"
}
file_name = file_map.get(self.proxy_type)
if not file_name:
raise ValueError(f"Tipo desconhecido: {self.proxy_type.")
file_path = os.path.join(os.path.dirname(__file__), file_name)
if not os.path.exists(file_path):
raise FileNotFoundError(f"Arquivo {file_name não encontrado.")
with open(file_path, 'r') as f:
lines = f.read().strip().splitlines()
# Adiciona o protocolo: protocol://line (line = user:pass@host:port ou host:port)
proxies = [f"{self.protocol://{line.strip()" for line in lines if line.strip()]
if not proxies:
raise ValueError(f"O arquivo {file_name está vazio.")
return proxies
def get_proxy(self):
"""Retorna um proxy."""
if not self.proxies:
raise ValueError("Sem proxies!")
if self.rotate:
self.current_proxy = random.choice(self.proxies)
else:
self.current_proxy = self.proxies[0]
return self.current_proxy
def get_proxy_config(self):
"""Retorna ProxyConfig para Crawl4AI."""
if not self.current_proxy:
self.get_proxy()
# Divide: protocol://user:pass@host:port ou protocol://host:port
if '@' in self.current_proxy:
parts = self.current_proxy.split('@')
auth = parts[0].split('//')[1] # user:pass
host_port = parts[1] # host:port
user, password = auth.split(':')
else:
host_port = self.current_proxy.split('//')[1] # host:port para no-auth
user, password = None, None
from crawl4ai.async_configs import ProxyConfig
return ProxyConfig(
server=f"{self.protocol://{host_port",
username=user,
password=password
)
def add_proxy(self, proxy_url):
self.proxies.append(proxy_url)
Passo 2. Script do scraper (scraper.py):
import asyncio
from crawl4ai import AsyncWebCrawler
from crawl4ai.async_configs import BrowserConfig
from proxy_module import ProxyManager
# Troca de tipo (residential, mobile, datacenter)
PROXY_TYPE = "residential"
# Troca de protocolo (http ou socks5 — socks5 apenas sem auth!)
PROXY_PROTOCOL = "http" # Recomendado para auth; para SOCKS5 remova login:password do arquivo
# Inicializamos o gerenciador
proxy_manager = ProxyManager(proxy_type=PROXY_TYPE, protocol=PROXY_PROTOCOL, rotate=True)
async def main():
try:
proxy_config = proxy_manager.get_proxy_config()
browser_config = BrowserConfig(proxy_config=proxy_config)
async with AsyncWebCrawler(verbose=True, config=browser_config) as crawler:
current_proxy = proxy_manager.get_proxy()
print(f"🚀 Iniciando via {PROXY_PROTOCOL.upper() proxy...")
print(f"Proxy: {current_proxy")
result = await crawler.arun(
url="https://ipinfo.io/json",
bypass_cache=True
)
if result.success:
print("\n✅ Sucesso! Resposta:")
print(result.markdown)
else:
print(f"\n❌ Erro: {result.error_message")
except Exception as e:
print(f"❌ Erro: {str(e)")
if __name__ == "__main__":
asyncio.run(main())
Passo 3. Execução:
python scraper.py
- Para SOCKS5: Defina PROXY_PROTOCOL = "socks5" e remova a autenticação dos arquivos (apenas host:porta). Se precisar de autenticação, use HTTP.
Parte 4. Cenários Avançados e Resolução de Problemas
Rotação Automática (para residenciais rotativos e móveis):
Não há necessidade de código extra — o gateway do CyberYozh App rotaciona o IP por si só. Apenas chame o crawler.arun em um loop:
for url in urls_list:
proxy_config = proxy_manager.get_proxy_config() # Nova config para rotação
browser_config = BrowserConfig(proxy_config=proxy_config)
# Reinicialize o crawler com a nova config, se necessário
result = await crawler.arun(url=url, bypass_cache=True)
Rotação Manual para Estáticos (residenciais/datacenter):
Adicione várias linhas no arquivo proxies_residential.txt ou proxies_datacenter.txt e use rotate=True. Ou utilize a troca de IP via link ou requisição de API.
Scraping em Massa com Pausas:
Adicione atrasos para imitar o comportamento humano:
import time
time.sleep(random.uniform(1, 5)) # Pausa de 1-5 seg antes da requisição
💡 Dica: alguns sites podem usar mecanismos de verificação baseados em CAPTCHA para impedir o acesso automatizado. Se surgirem problemas assim no seu fluxo de trabalho, você pode integrar um serviço de terceiros para resolução de CAPTCHA, como o CapSolver. Ele suporta reCAPTCHA v2/v3, Cloudflare Turnstile, Challenge, AWS WAF e outros. Certifique-se de que seu uso esteja em conformidade com os termos de serviço do site alvo e com as leis aplicáveis.
Resolução de Problemas:
- Erro de conexão: Verifique o formato nos arquivos (login:senha@host:porta). Teste o proxy no navegador.
- Bloqueio apesar do proxy: Aumente as pausas ou mude o tipo (para móveis em sites mais rígidos). Ative o modo stealth no Crawl4AI: browser_type="undetected" no BrowserConfig.
- Erros de Playwright: Certifique-se de que o playwright install foi executado. Se headless=False, o navegador abrirá visivelmente para depuração.
- Erro de auth SOCKS5: O Playwright não suporta — use proxies HTTP.
- Exceções de Asyncio: Ignore; é uma particularidade do Windows, não afeta o funcionamento.
- Log: Ative verbose=True no Crawl4AI para logs detalhados.
Conclusão
O Crawl4AI + proxies do CyberYozh App — o par ideal para coleta de dados sem bloqueios. Escolha:
- Residenciais Rotativos para datasets em massa (Amazon/Google).
- Móveis Compartilhados (Shared) para redes sociais e sites protegidos.
- Residenciais Estáticos para tarefas que exigem sessão.
- Datacenter Estáticos para coletas de dados simples e rápidas.
Vá até o catálogo do CyberYozh App, escolha os proxies adequados, configure o Crawl4AI e escale seu scraping para IA.
Documentação adicional: Crawl4AI GitHub