Настройка прокси в Crawl4AI
Crawl4AI — это мощный open-source инструмент для веб-скрапинга, предназначенный для извлечения чистых данных с веб-страниц, подходящих для обучения ИИ и LLM-моделей. Он быстрый, гибкий и способен обходить базовые защиты сайтов, такие как простые анти-бот системы. Для более сложных защит, включая CAPTCHA, рекомендуется интеграция со сторонними сервисами (см. Часть 4).
Однако при масштабном скрапинге (например, 10 000 страниц) ваш локальный IP-адрес быстро попадёт под блокировку. Чтобы избежать этого и обеспечить непрерывный поток данных для ваших AI-моделей, необходима надёжная прокси-инфраструктура. В этом гайде мы разберём, как выбрать подходящий тип прокси от CyberYozh App для вашей задачи и интегрировать их в Crawl4AI.
🛑 Критически важная информация по протоколам (HTTP vs SOCKS5): Библиотека Playwright (на которой работает Crawl4AI) не поддерживает SOCKS5-прокси с авторизацией (login:password). Так как все прокси в CyberYozh App для безопасности работают только с авторизацией, для работы с Crawl4AI вам необходимо использовать протокол HTTP. Он полностью поддерживает авторизацию и обеспечивает стабильную работу.
Ключевые особенности интеграции: Прокси — отдельный модуль (proxy_module.py) для модульности. Данные хранятся в текстовых файлах (по типу: резидентские, мобильные, датацентр). Переключение типа/протокола — в одной-двух строках в основном скрипте.
Часть 1. Выбор прокси: Какой тип подойдёт для вашего датасета?
Crawl4AI универсален, но эффективность зависит от "топлива" — пула IP-адресов. В CyberYozh App доступны различные типы прокси, каждый оптимизирован для конкретных сценариев скрапинга. Выбор зависит от уровня защиты сайта, объёма данных и необходимости в ротации. Все типы поддерживают как HTTP, так и SOCKS5.
- Резидентские Ротационные (Residential Rotating) — Выбор №1 для массового скрапинга
- Суть: Пул из миллионов реальных домашних IP-адресов. Ротация автоматически: новый IP по ссылке или по запросу API.
- Идеально для Crawl4AI: Большие датасеты с маркетплейсов (Amazon, Wildberries), поисковиков (Google, Yandex).
- Почему: Высокий траст, минимизирует блокировки. Поддерживают 3 вида сессий (Случайный IP, Короткая, Длинная до 6 часов).
- Резидентские Статические (Residential Static / ISP)
- Суть: Фиксированные домашние IP на период аренды.
- Идеально для Crawl4AI: Сайты с авторизацией (личные кабинеты).
- Почему: Стабильность сессий.
- Мобильные выделенные порты (Mobile Dedicated)
- Суть: Приватный модем с реальной SIM-картой, выделенный лично под вас.
- Идеально для Crawl4AI: Сложные задачи, сайты с жесткой анти-бот защитой, эмуляция поведения реального пользователя мобильного устройства.
- Почему: Максимальный траст со стороны сайтов. Рекомендуется для самых тяжелых кейсов.
- Мобильные общие прокси (Mobile Shared)
- Суть: IP от 4G/5G, shared-канал в приватном режиме.
- Идеально для Crawl4AI: Соцсети (Instagram, TikTok) или сайты с защитой (Cloudflare).
- Почему: Высокий траст для мобильного трафика.
- Датацентровые выделенные прокси (Datacenter)
- Суть: Серверные IP, быстрые и дешёвые.
- Идеально для Crawl4AI: Открытые источники без защиты.
- Почему: Максимальная скорость.
Совет по интеграции: Для смешанного подхода комбинируйте типы.
Часть 2. Подготовка данных и установка
Подготовьте данные из CyberYozh App:
После покупки прокси скопируйте данные:
- Host (IP): 51.77.190.247
- Port: 5959
- Login: user123
- Password: pass123
Формат строки подключения: Crawl4AI (как и библиотека Playwright, лежащая в его основе) принимает прокси в формате единой строки: http://login:password@ip:port
Пример: http://user123:pass123@51.77.190.247:5959
Управление Резидентскими ротационными прокси
Для Резидентских Ротационных прокси в CyberYozh App доступна гибкая настройка сессии прямо через логин (username). Это критически важно для логики вашего скрапера.
Креды можно сгенерировать в личном кабинете, нажав кнопку “Сгенерировать учетные данные” в карточке пакета. Доступны форматы вывода: IP:PORT:USERNAME:PASSWORD или ссылка для cURL.
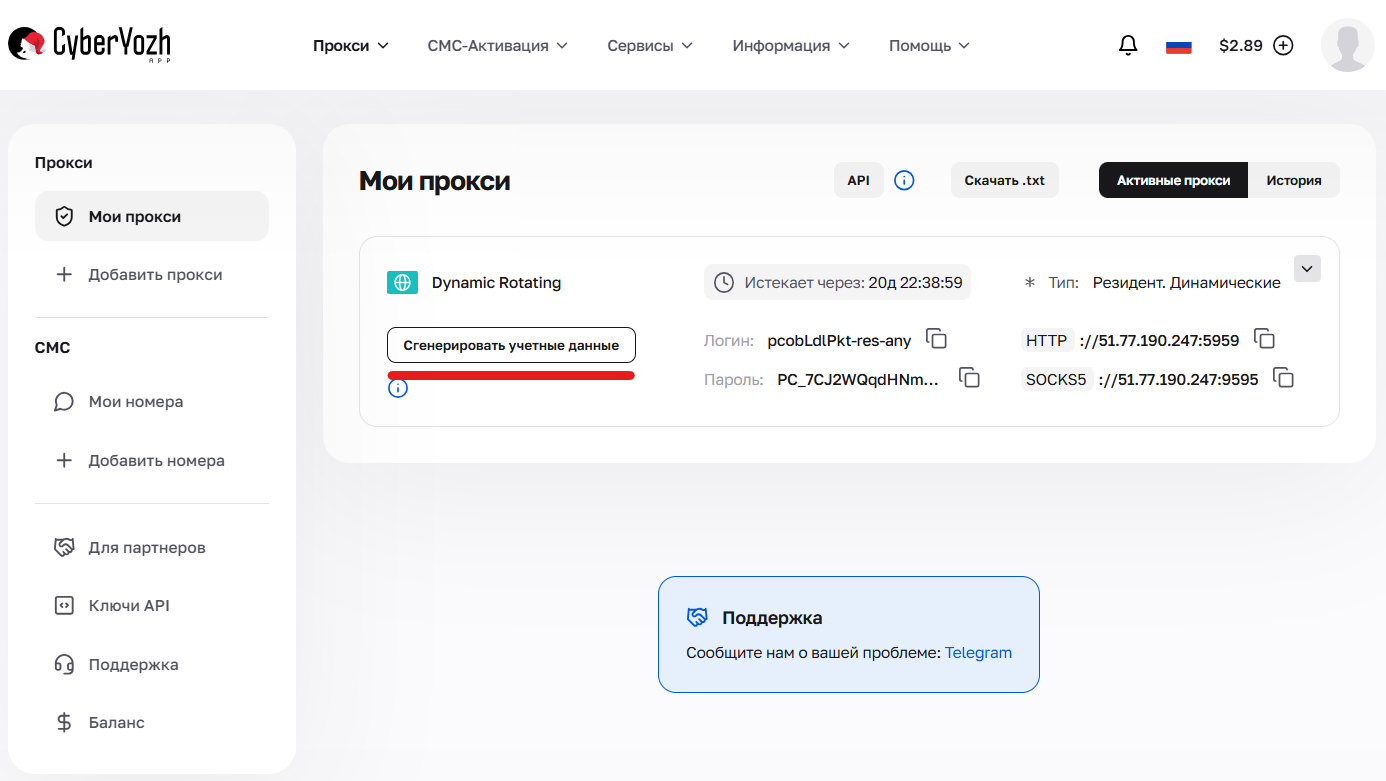
Рис. 1. Переход к интерфейсу создания конфигураций и параметров подключения (генератор кредов).
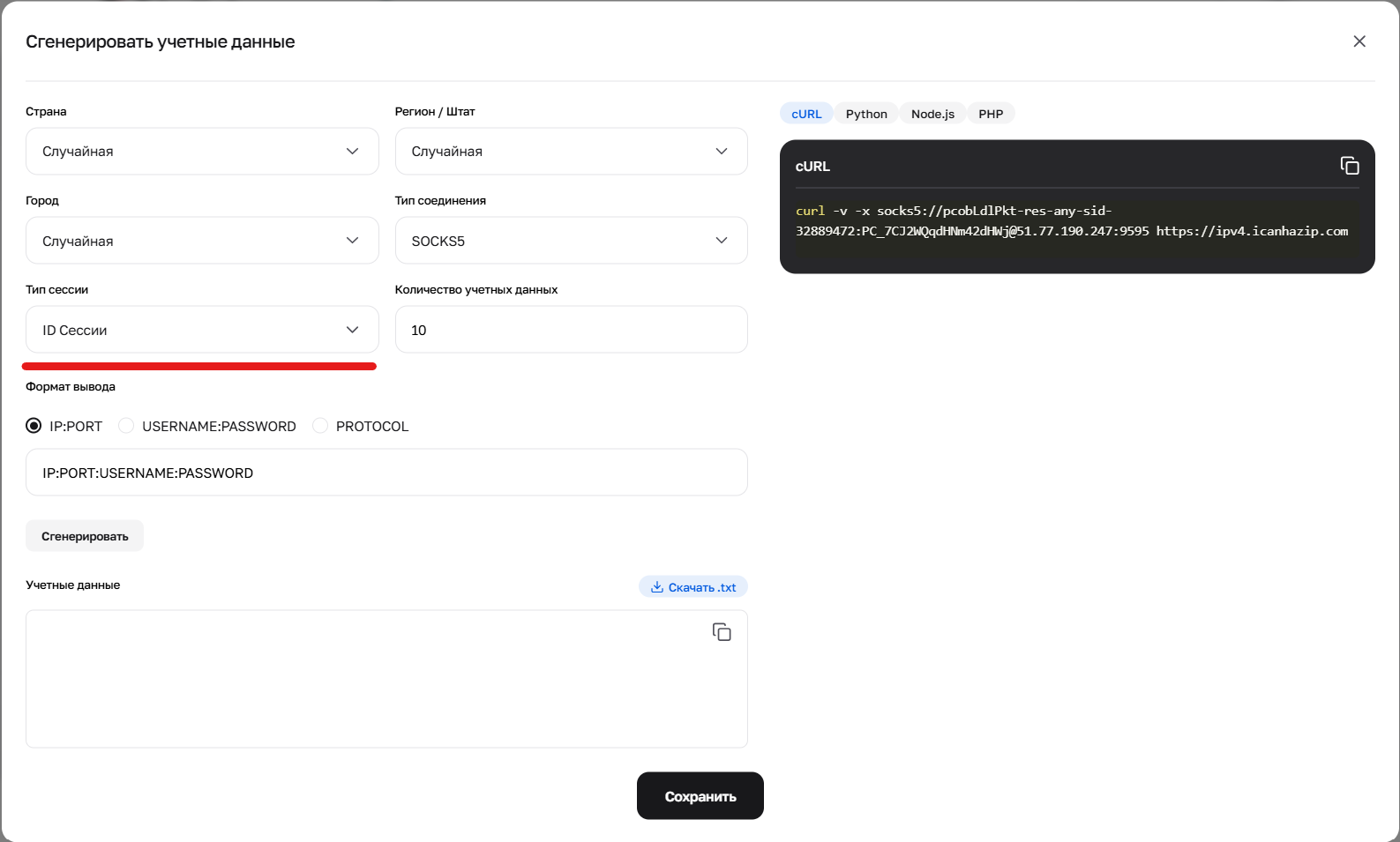
Рис. 2. Использование генератора для настройки параметра sid, отвечающего за создание новых уникальных сессий.
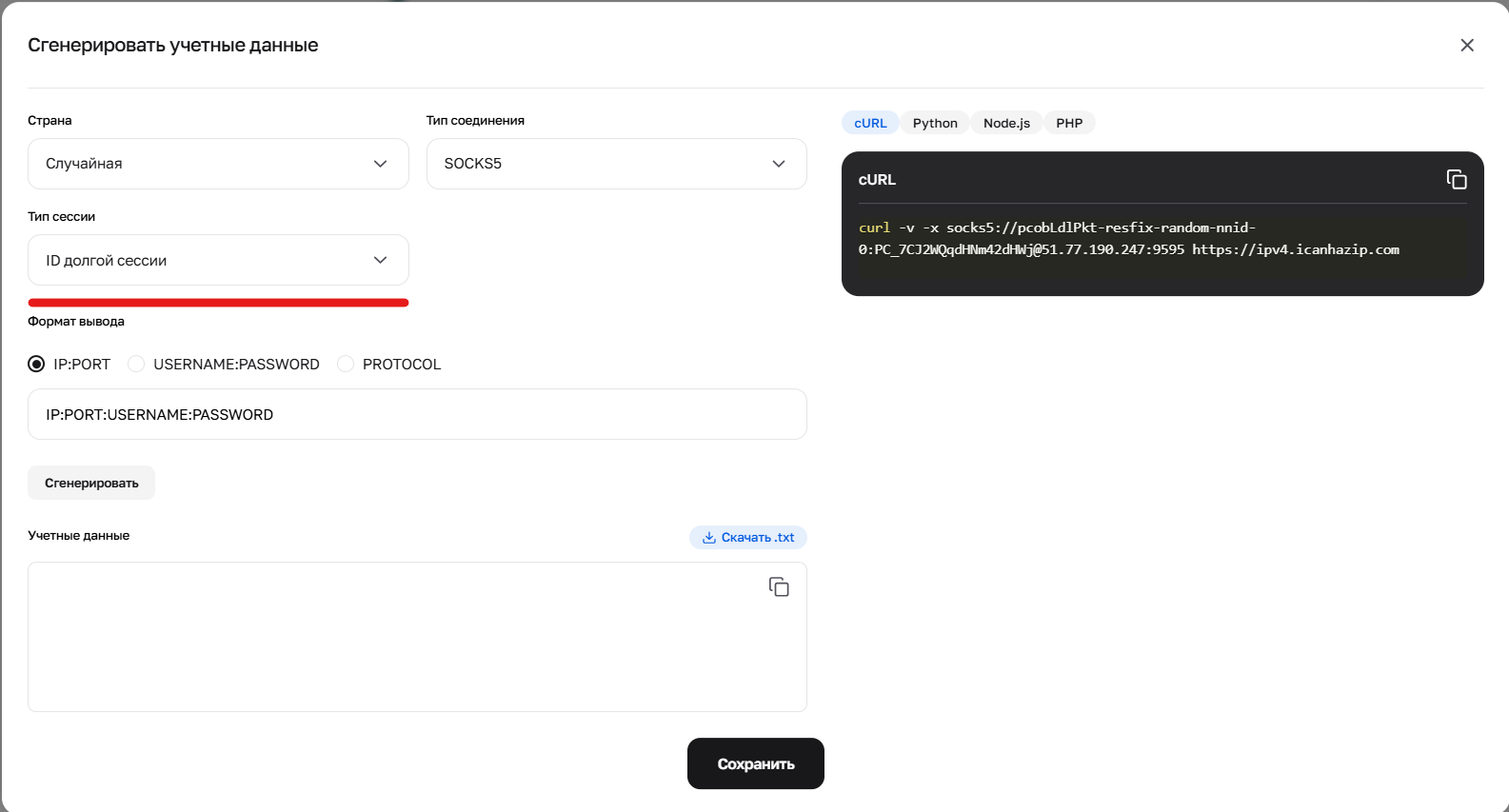
Рис. 3. Настройка параметров для формирования учетных данных с использованием длинных (Sticky) сессий.
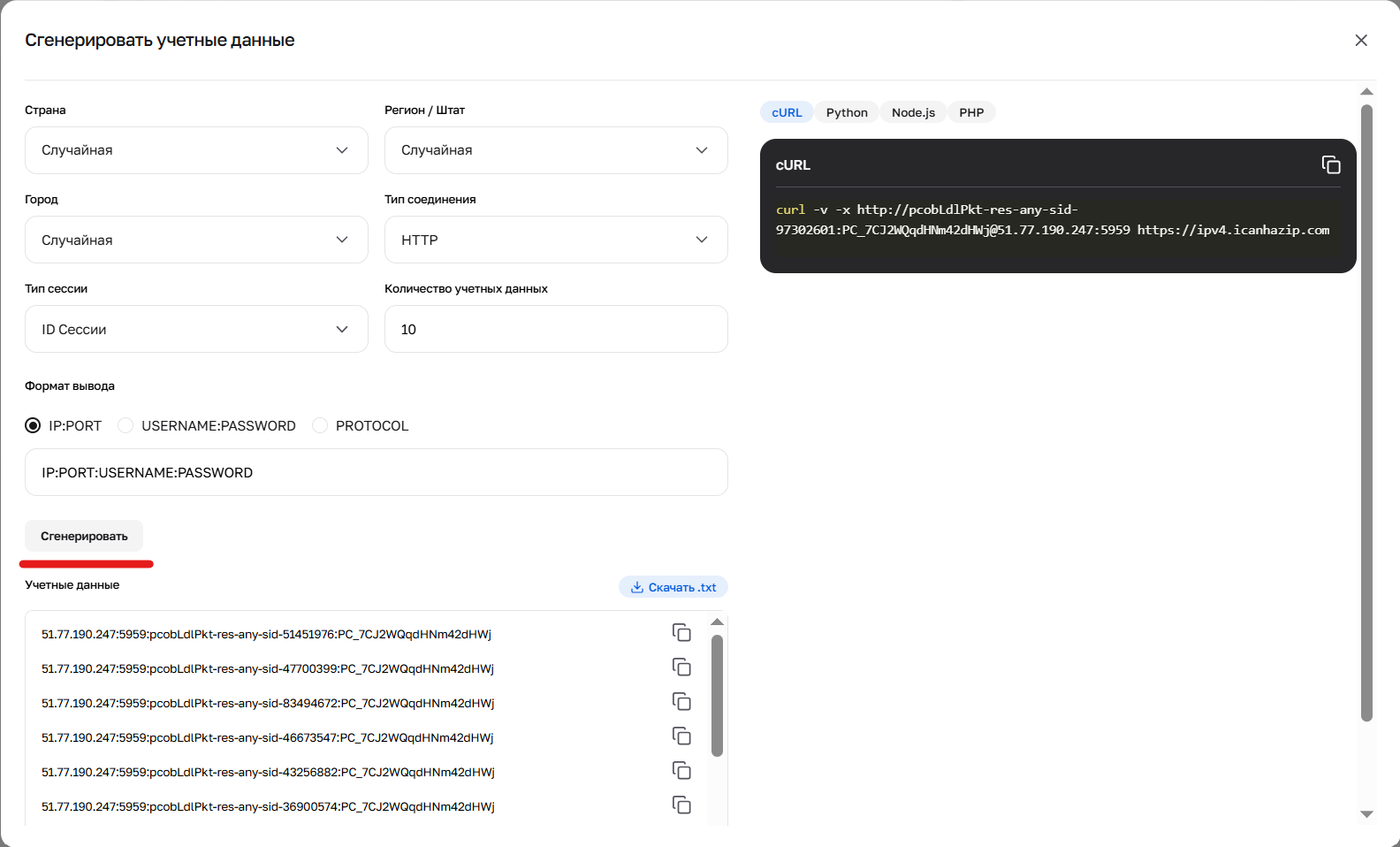
Рис. 4. Результат работы генератора учётных данных (кредов).
Типы сессий и как их прописать:
1. Случайный IP (Random IP) — для каждого запроса новый IP Используйте префикс -res-any. Пример логина: user-res-any Когда нужно: Обычный скрапинг, где не нужно сохранять состояние между страницами.
2. Короткая сессия (до 1 минуты) Позволяет сохранить IP на короткое время (например, пройти капчу и загрузить страницу). Используйте префикс -sid-RANDOMNUMBER.
Формат: user-res-any-sid-47551677 (где 47551677 — любое случайное число, генерируемое вами).
Гео: В коротких сессиях можно выбрать Страну, Регион и Город (пример: -res_sc-us_georgia_macon-sid-54683597).
3. Длинная липкая сессия (до 6 часов) Это Sticky-сессия, которая держит один IP до 6 часов. Идеально для глубокого парсинга одного сайта.
Как получить: Вариант А (Простой): Сгенерировать готовую строку с "Длинной сессией" в генераторе учётных данных (кредов) в личном кабинете. Вариант Б (Продвинутый/API): Необходимо выполнить 2 шага. Сделать запрос cURL с префиксом -resfix- (например, user-resfix-us-nnid-0). В заголовке ответа X-NN-LLS получить токен (например, 9d016e26...). Подставить этот токен вместо 0 в логин: user-resfix-us-nnid-9d016e26....
Управление мобильными прокси в личном кабинете
Работа с мобильными прокси имеет важную особенность: для смены IP используется API-ссылка. Обязательно найдите её в карточке купленного пакета — именно этот URL необходимо вставить в ваш софт или скрипт для настройки автоматической ротации.
Рис. 5. Расположение ссылки для автоматической ротации.
Кроме того, в CyberYozh App предусмотрен ручной режим. Если вам требуется сменить IP-адрес прямо сейчас, не прибегая к скриптам, просто нажмите кнопку смены IP в панели управления — адрес обновится мгновенно.
Рис. 6. Кнопка для принудительной ручной смены.
Создайте файлы в директории проекта:
proxies_residential.txt:
user123:pass123@51.77.190.247:5959 Добавьте больше прокси для ротации.
proxies_mobile.txt и proxies_datacenter.txt аналогично. * Формат: login:password@host:port для auth (только с HTTP).
Установка:
pip install crawl4ai playwright
playwright install
Проверьте установку: python -m crawl4ai --version. Используйте venv, если необходимо.
Часть 3. Интеграция прокси в Crawl4AI (Python) как отдельный модуль
Модуль proxy_module.py загружает прокси из файлов, добавляет протокол ("http" или "socks5") и поддерживает ротацию.
Шаг 1. Модуль прокси (proxy_module.py):
import random
import os
class ProxyManager:
def __init__(self, proxy_type="residential", protocol="http", rotate=True):
"""
Инициализация менеджера прокси.
:param proxy_type: Тип ('residential', 'mobile', 'datacenter')
:param protocol: Протокол ('http' или 'socks5') — socks5 только без auth!
:param rotate: Вкл/выкл ротацию
"""
self.proxy_type = proxy_type.lower()
self.protocol = protocol.lower()
self.rotate = rotate
self.proxies = self._load_proxies() # Загружаем из файла
if self.protocol == "socks5" and self.proxies and '@' in self.proxies[0]: # Проверка на auth
raise ValueError("SOCKS5 не поддерживает аутентификацию в Playwright! Удалите login:password из файла.")
self.current_proxy = None
def _load_proxies(self):
"""Загружает прокси из файла."""
file_map = {
"residential": "proxies_residential.txt",
"mobile": "proxies_mobile.txt",
"datacenter": "proxies_datacenter.txt"
}
file_name = file_map.get(self.proxy_type)
if not file_name:
raise ValueError(f"Неизвестный тип: {self.proxy_type}.")
file_path = os.path.join(os.path.dirname(__file__), file_name)
if not os.path.exists(file_path):
raise FileNotFoundError(f"Файл {file_name} не найден.")
with open(file_path, 'r') as f:
lines = f.read().strip().splitlines()
# Добавляем протокол: protocol://line (line = user:pass@host:port или host:port)
proxies = [f"{self.protocol}://{line.strip()}" for line in lines if line.strip()]
if not proxies:
raise ValueError(f"Файл {file_name} пустой.")
return proxies
def get_proxy(self):
"""Возвращает прокси."""
if not self.proxies:
raise ValueError("Нет прокси!")
if self.rotate:
self.current_proxy = random.choice(self.proxies)
else:
self.current_proxy = self.proxies[0]
return self.current_proxy
def get_proxy_config(self):
"""Возвращает ProxyConfig для Crawl4AI."""
if not self.current_proxy:
self.get_proxy()
# Разделяем: protocol://user:pass@host:port или protocol://host:port
if '@' in self.current_proxy:
parts = self.current_proxy.split('@')
auth = parts[0].split('//')[1] # user:pass
host_port = parts[1] # host:port
user, password = auth.split(':')
else:
host_port = self.current_proxy.split('//')[1] # host:port для no-auth
user, password = None, None
from crawl4ai.async_configs import ProxyConfig
return ProxyConfig(
server=f"{self.protocol}://{host_port}",
username=user,
password=password
)
def add_proxy(self, proxy_url):
self.proxies.append(proxy_url)
Шаг 2. Скрипт скрапера (scraper.py):
import asyncio
from crawl4ai import AsyncWebCrawler
from crawl4ai.async_configs import BrowserConfig
from proxy_module import ProxyManager
# Переключение типа (residential, mobile, datacenter)
PROXY_TYPE = "residential"
# Переключение протокола (http или socks5 — socks5 только без auth!)
PROXY_PROTOCOL = "http" # Рекомендуется для auth; для SOCKS5 уберите login:password из файла
# Инициализируем менеджер
proxy_manager = ProxyManager(proxy_type=PROXY_TYPE, protocol=PROXY_PROTOCOL, rotate=True)
async def main():
try:
proxy_config = proxy_manager.get_proxy_config()
browser_config = BrowserConfig(proxy_config=proxy_config)
async with AsyncWebCrawler(verbose=True, config=browser_config) as crawler:
current_proxy = proxy_manager.get_proxy()
print(f"🚀 Запуск через {PROXY_PROTOCOL.upper()} прокси...")
print(f"Прокси: {current_proxy}")
result = await crawler.arun(
url="https://ipinfo.io/json",
bypass_cache=True
)
if result.success:
print("\n✅ Успешно! Ответ:")
print(result.markdown)
else:
print(f"\n❌ Ошибка: {result.error_message}")
except Exception as e:
print(f"❌ Ошибка: {str(e)}")
if __name__ == "__main__":
asyncio.run(main())
Шаг 3. Запуск:
python scraper.py
- Для SOCKS5: Установите PROXY_PROTOCOL = "socks5" и уберите auth из файлов (только host:port). Если auth нужен — используйте "http".
Часть 4. Продвинутые сценарии и решение проблем
Автоматическая ротация (для резидентских ротационных и мобильных):
Нет нужды в коде — шлюз CyberYozh App сам ротирует IP. Просто вызывайте crawler.arun в цикле:
for url in urls_list:
proxy_config = proxy_manager.get_proxy_config() # Новый конфиг для ротации
browser_config = BrowserConfig(proxy_config=proxy_config)
# Переинициализируйте crawler с новым config, если нужно
result = await crawler.arun(url=url, bypass_cache=True)
Ручная ротация для статических (резидентских/датацентр):
Добавьте несколько строк в файл proxies_residential.txt или proxies_datacenter.txt и используйте rotate=True. Либо используйте смену IP по ссылке или запросу API.
Массовый скрапинг с паузами:
Добавьте задержки для имитации человеческого поведения:
import time
time.sleep(random.uniform(1, 5)) # Пауза 1-5 сек перед запросом
💡 Совет: некоторые веб-сайты могут использовать механизмы проверки на основе CAPTCHA для предотвращения автоматического доступа. Если в вашем рабочем процессе возникают такие проблемы, вы можете интегрировать сторонний сервис обработки CAPTCHA, такой как CapSolver. Он поддерживает reCAPTCHA v2/v3, Cloudflare Turnstile, Challenge, AWS WAF и другие. Убедитесь, что ваше использование соответствует условиям обслуживания целевого веб-сайта и применимым законам.
Решение проблем:
- Ошибка подключения: Проверьте формат в файлах (login:password@host:port). Тестируйте прокси в браузере.
- Блокировка несмотря на прокси: Увеличьте паузы или смените тип (на мобильные для жёстких сайтов). Добавьте stealth mode в Crawl4AI: browser_type="undetected" в BrowserConfig.
- Playwright ошибки: Убедитесь, что playwright install выполнен. Если headless=False, браузер откроется visibly для отладки.
- SOCKS5 auth ошибка: Playwright не поддерживает — используйте HTTP прокси.
- Asyncio исключения: Игнорируйте; это Windows-специфика, не влияет.
- Логирование: Вклюйте verbose=True в Crawl4AI для детальных логов.
Заключение
Crawl4AI + прокси от CyberYozh App — идеальный дуэт для сбора данных без блокировок. Выберите:
- Резидентские Ротационные для массовых датасетов (Amazon/Google).
- Мобильные Общие (Shared) для соцсетей и защищённых сайтов.
- Резидентские Статические для сессионных задач.
- Датацентровые Статические для простых и быстрых сборов данных.
Перейдите в каталог CyberYozh App, выберите подходящие прокси, настройте Crawl4AI и масштабируйте свой AI-скрапинг.
Дополнительная документация: Crawl4AI GitHub