在Crawl4AI中配置代理
Crawl4AI — 是一款强大的开源网页爬虫工具,旨在从网页中提取纯净数据,适用于训练人工智能(AI)和大型语言模型(LLM)。它速度快、灵活性高,并能绕过基础的网站防护(如简单的反爬虫系统)。对于包含验证码(CAPTCHA)在内的更复杂防护,建议集成第三方服务(详见第 4 部分)。
然而,在进行大规模抓取(例如 10,000 个页面)时,您的本地 IP 地址很快就会被封锁。为了避免这种情况并为您的 AI 模型确保连续的数据流,可靠的代理基础设施必不可少。在本指南中,我们将探讨如何为您的任务从 CyberYozh App 选择合适的代理类型,并将其集成到 Crawl4AI 中。
🛑 关于协议的关键信息(HTTP vs SOCKS5): Playwright 库(Crawl4AI 的运行基础)不支持带身份验证(login:password)的 SOCKS5 代理。由于 CyberYozh App 中的所有代理出于安全考虑仅支持身份验证,因此要在 Crawl4AI 中使用,您必须使用 HTTP 协议。它完全支持身份验证并能确保稳定运行。
集成核心特性: 代理作为一个独立模块(proxy_module.py)以实现模块化。数据存储在文本文件中(按类型分类:住宅、移动、数据中心)。在主脚本中仅需一两行代码即可切换类型或协议。
第 1 部分。选择代理:哪种类型适合您的数据集?
Crawl4AI 功能全面,但效率取决于“燃料” — 即 IP 地址池。CyberYozh App 提供多种代理类型,每种都针对特定的抓取场景进行了优化。选择取决于网站的防护级别、数据量以及是否需要轮换。所有类型均支持 HTTP 和 SOCKS5。
- 动态住宅代理 (Residential Rotating) — 大规模抓取的首选
- 核心: 拥有数百万个真实家庭 IP 地址的池。自动轮换:通过链接或 API 请求获取新 IP。
- Crawl4AI 的理想选择: 来自电商平台(Amazon、Wildberries)、搜索引擎(Google、Yandex)的大型数据集。
- 原因: 高信任度,最大限度减少封锁。支持 3 种会话模式(随机 IP、短效会话、长达 6 小时的长效会话)。
- 静态住宅代理 (Residential Static / ISP)
- 核心: 租用期内固定的家庭 IP。
- Crawl4AI 的理想选择: 需要登录的网站(个人账户)。
- 原因: 会话稳定性高。
- 移动专属端口 (Mobile Dedicated)
- 核心: 带有真实 SIM 卡的专用私有调制解调器,仅供您个人使用。
- Crawl4AI 的理想选择: 复杂任务、具有严密反爬保护的网站、模拟真实移动端用户的行为。
- 原因: 网站信任度最高。推荐用于最困难的场景。
- 移动共享代理 (Mobile Shared)
- 核心: 来自 4G/5G 的 IP,私有模式下的共享通道。
- Crawl4AI 的理想选择: 社交网络(Instagram、TikTok)或具有防护(如 Cloudflare)的网站。
- 原因: 移动流量的高信任度。
- 数据中心专属代理 (Datacenter)
- 核心: 服务器 IP,速度快且价格低廉。
- Crawl4AI 的理想选择: 无防护的公开数据源。
- 原因: 速度极快。
集成建议: 对于混合抓取需求,可以组合使用不同类型的代理。
第 2 部分。准备数据与安装
从 CyberYozh App 准备数据:
购买代理后,请复制相关数据:
- Host (IP): 51.77.190.247
- Port: 5959
- Login: user123
- Password: pass123
连接字符串格式: Crawl4AI(及其底层的 Playwright 库)接收单一字符串格式的代理:http://login:password@ip:port
示例:http://user123:pass123@51.77.190.247:5959
管理动态住宅代理
对于 CyberYozh App 中的动态住宅代理,您可以直接通过用户名(username)灵活设置会话。这对于爬虫的逻辑至关重要。
可以在个人中心点击套餐卡片上的 “生成凭据” 按钮来生成账号信息。支持的输出格式:IP:PORT:USERNAME:PASSWORD 或 cURL 链接。
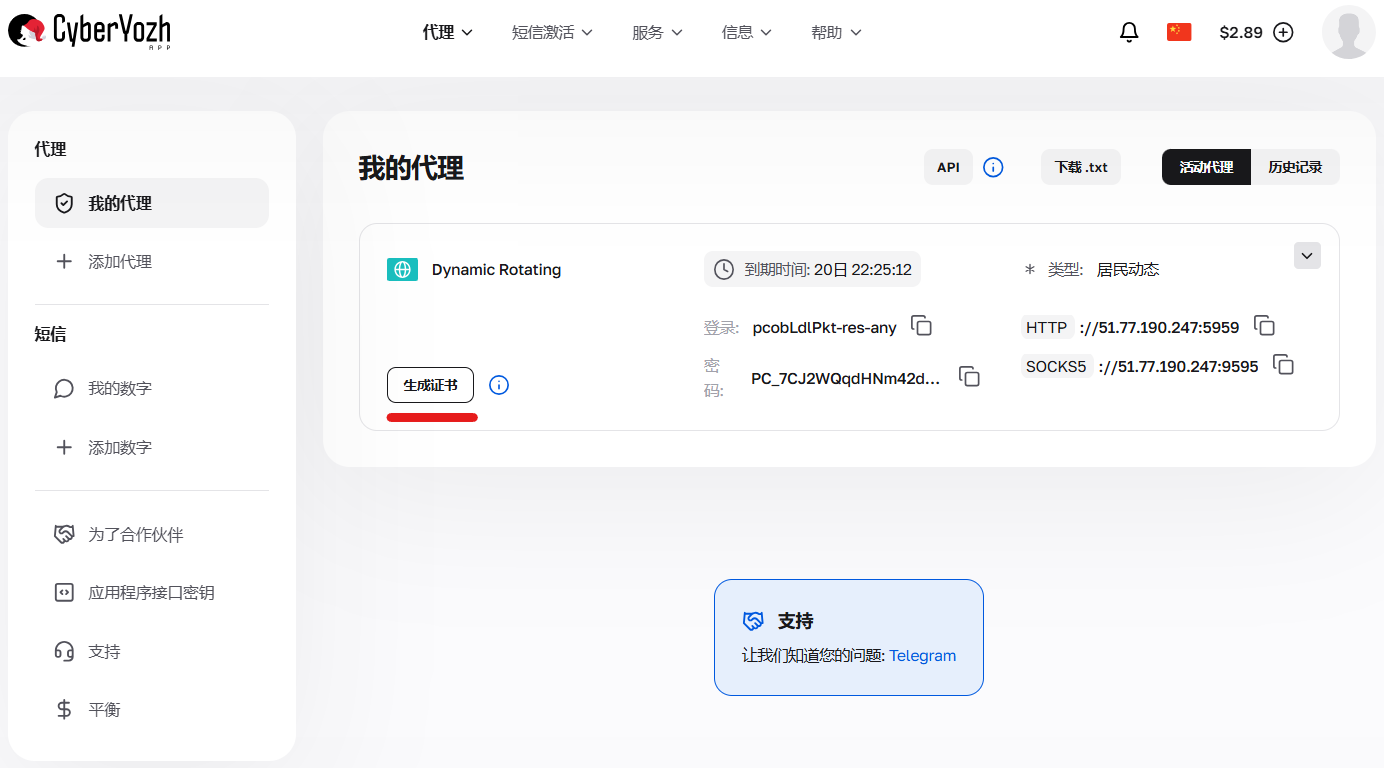
图 1. 前往创建配置和连接参数的界面(凭据生成器)。
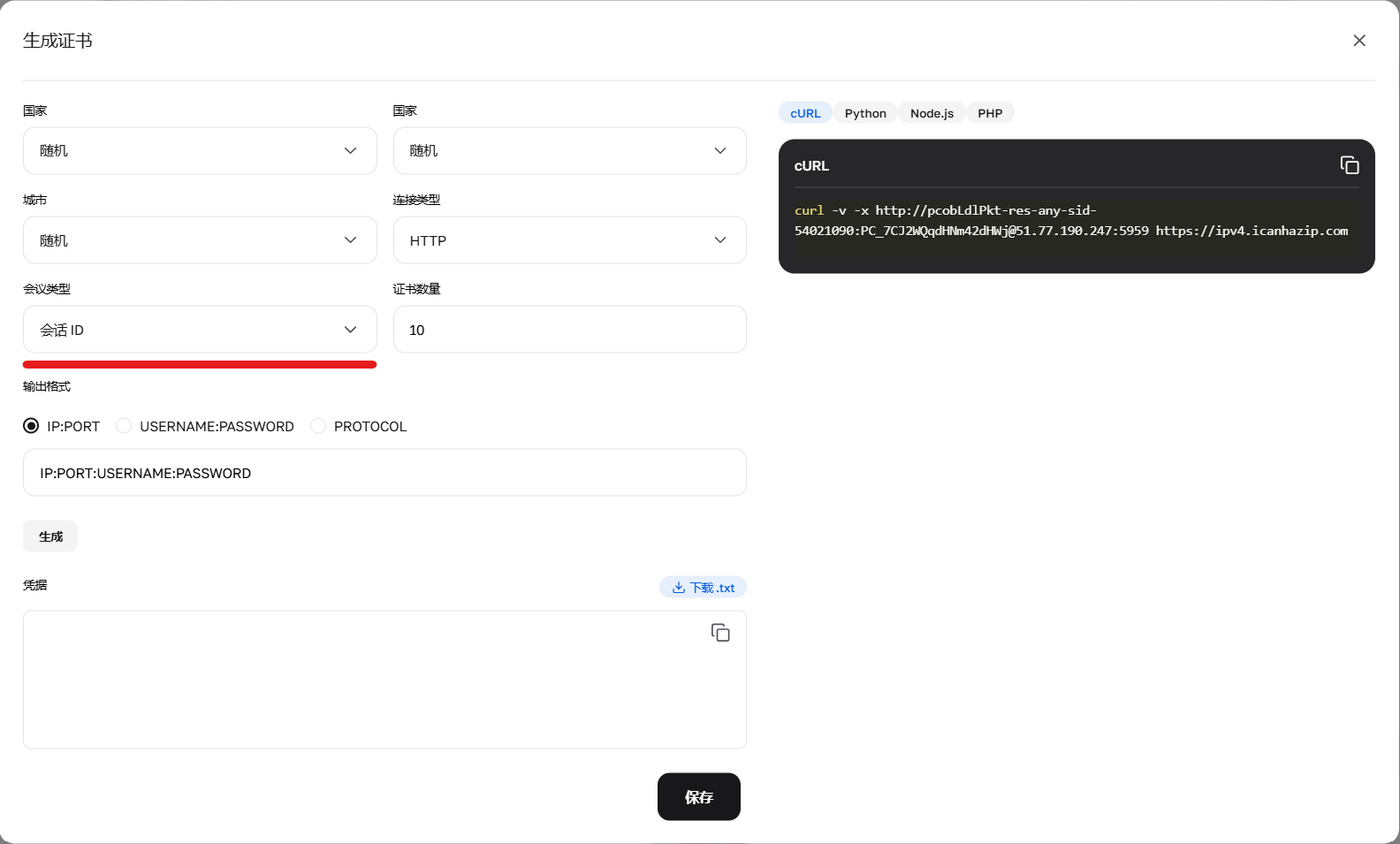
图 2. 使用生成器设置 sid 参数,负责创建新的唯一会话。
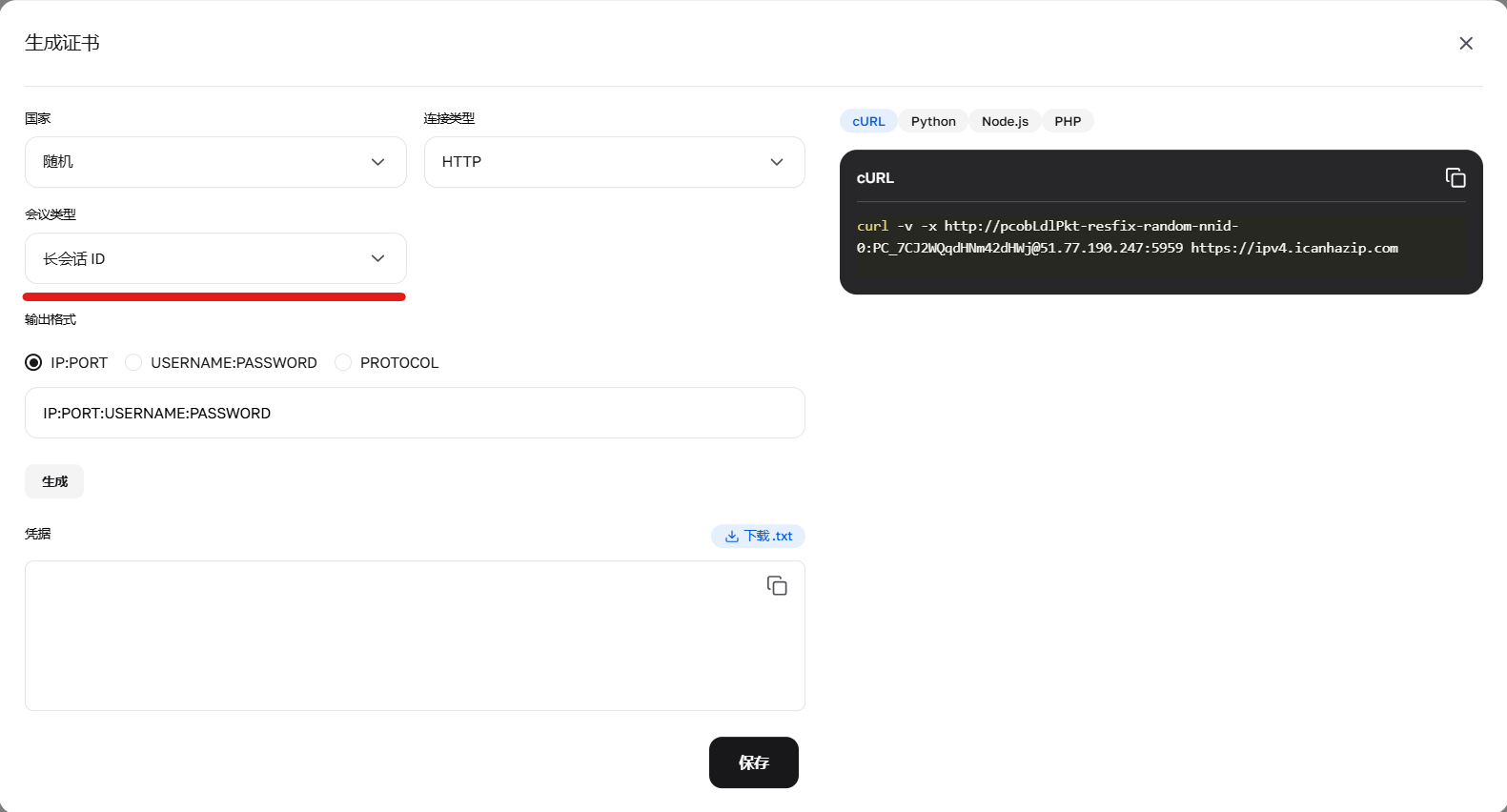
图 3. 使用长效(Sticky)会话配置凭据参数。
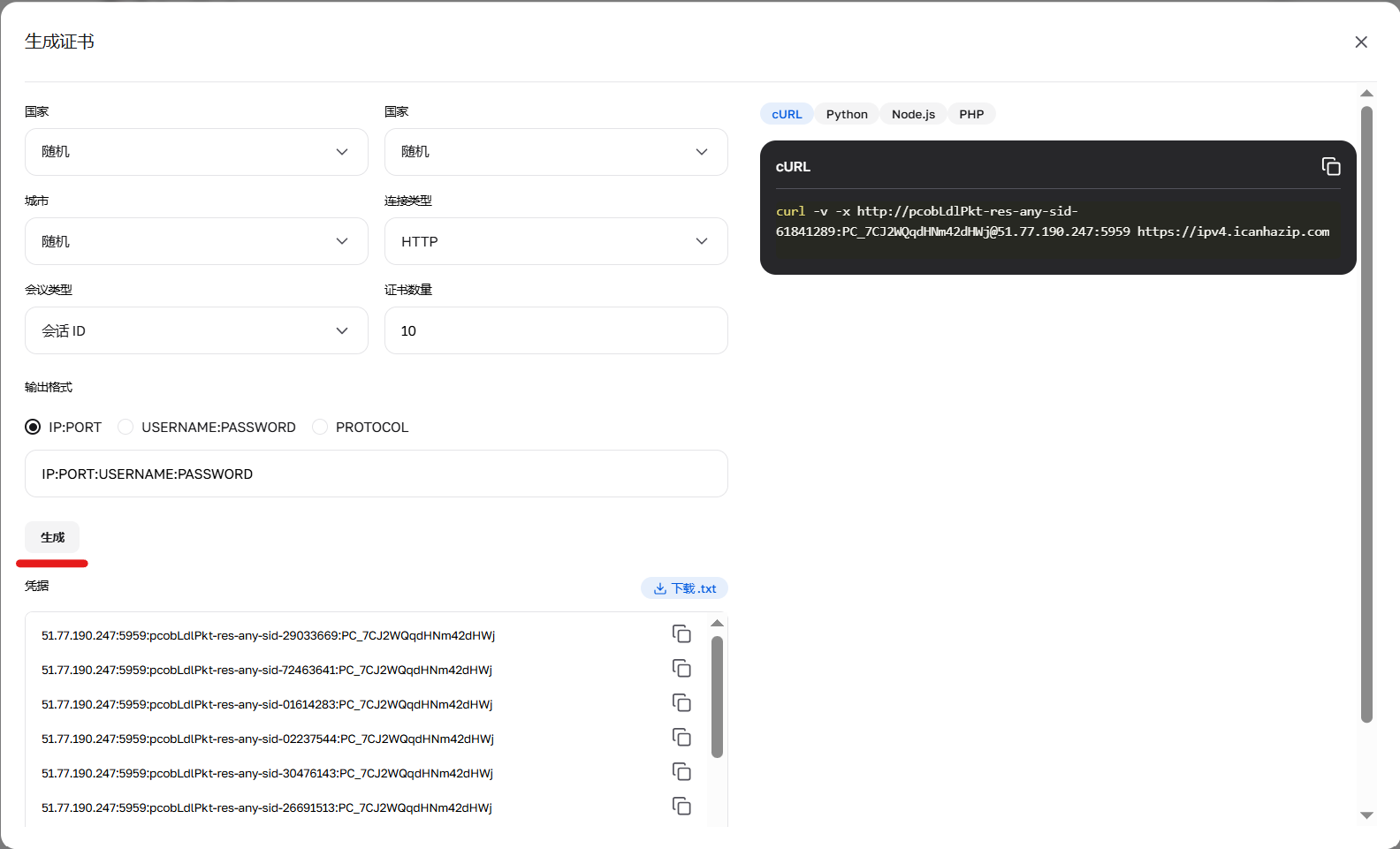
图 4. 账号凭据生成器的运行结果。
会话类型及设置方法:
1. 随机 IP (Random IP) — 每次请求获取新 IP 使用前缀 -res-any。登录名示例: user-res-any 适用场景: 不需要跨页面保持状态的普通抓取。
2. 短效会话 (长达 1 分钟) 允许短时间内保持 IP(例如,通过验证码并加载页面)。使用前缀 -sid-RANDOMNUMBER。
格式: user-res-any-sid-47551677(其中 47551677 是您生成的任意随机数)。
地理位置: 在短效会话中,您可以选择国家、地区和城市(例如:-res_sc-us_georgia_macon-sid-54683597)。
3. 固定长效会话 (长达 6 小时) 这种 Sticky 会话可将同一个 IP 保持长达 6 小时。非常适合对单个网站进行深度爬取。
获取方法: 方案 A (简单): 在个人中心的凭据生成器中直接生成带有“长效会话”的字符串。方案 B (进阶/API): 需要分两步:使用前缀 -resfix- 发送 cURL 请求(例如 user-resfix-us-nnid-0);从响应头 X-NN-LLS 中获取 Token(例如 9d016e26...);将该 Token 替换登录名中的 0:user-resfix-us-nnid-9d016e26...。
在个人中心管理移动代理
操作移动代理有一个重要特点:需使用 API 链接 来更换 IP。请务必在已购套餐的卡片中找到它 — 正是这个 URL 需要放入您的软件或脚本中以设置自动轮换。
图 5. 自动轮换链接的位置。
此外,CyberYozh App 还提供了手动模式。如果您需要立即更换 IP 地址而不使用脚本,只需在控制面板中点击更换 IP 按钮 — 地址将立即更新。
图 6. 强制手动更换按钮。
在项目目录中创建文件:
proxies_residential.txt:
user123:pass123@51.77.190.247:5959 添加更多代理以便轮换。
proxies_mobile.txt 和 proxies_datacenter.txt 依此类推。* 格式:login:password@host:port 用于身份验证(仅限 HTTP)。
安装:
pip install crawl4ai playwright
playwright install
检查安装:python -m crawl4ai --version。如有需要,请使用 venv。
第 3 部分。将代理作为独立模块集成到 Crawl4AI (Python) 中
模块 proxy_module.py 从文件中加载代理,添加协议("http" 或 "socks5")并支持轮换。
步骤 1. 代理模块 (proxy_module.py):
import random
import os
class ProxyManager:
def __init__(self, proxy_type="residential", protocol="http", rotate=True):
"""
初始化代理管理器。
:param proxy_type: 类型 ('residential', 'mobile', 'datacenter')
:param protocol: 协议 ('http' 或 'socks5') — socks5 仅支持无身份验证!
:param rotate: 开启/关闭轮换
"""
self.proxy_type = proxy_type.lower()
self.protocol = protocol.lower()
self.rotate = rotate
self.proxies = self._load_proxies() # 从文件加载
if self.protocol == "socks5" and self.proxies and '@' in self.proxies[0]: # 检查验证信息
raise ValueError("Playwright 中的 SOCKS5 不支持身份验证!请从文件中删除 login:password。")
self.current_proxy = None
def _load_proxies(self):
"""从文件加载代理。"""
file_map = {
"residential": "proxies_residential.txt",
"mobile": "proxies_mobile.txt",
"datacenter": "proxies_datacenter.txt"
}
file_name = file_map.get(self.proxy_type)
if not file_name:
raise ValueError(f"未知类型: {self.proxy_type}。")
file_path = os.path.join(os.path.dirname(__file__), file_name)
if not os.path.exists(file_path):
raise FileNotFoundError(f"文件 {file_name} 未找到。")
with open(file_path, 'r') as f:
lines = f.read().strip().splitlines()
# 添加协议: protocol://line (line = user:pass@host:port 或 host:port)
proxies = [f"{self.protocol://{line.strip()" for line in lines if line.strip()]
if not proxies:
raise ValueError(f"文件 {file_name 为空。")
return proxies
def get_proxy(self):
"""返回代理。"""
if not self.proxies:
raise ValueError("没有代理!")
if self.rotate:
self.current_proxy = random.choice(self.proxies)
else:
self.current_proxy = self.proxies[0]
return self.current_proxy
def get_proxy_config(self):
"""返回 Crawl4AI 专用的 ProxyConfig。"""
if not self.current_proxy:
self.get_proxy()
# 分离: protocol://user:pass@host:port 或 protocol://host:port
if '@' in self.current_proxy:
parts = self.current_proxy.split('@')
auth = parts[0].split('//')[1] # user:pass
host_port = parts[1] # host:port
user, password = auth.split(':')
else:
host_port = self.current_proxy.split('//')[1] # host:port 无验证模式
user, password = None, None
from crawl4ai.async_configs import ProxyConfig
return ProxyConfig(
server=f"{self.protocol://{host_port",
username=user,
password=password
)
def add_proxy(self, proxy_url):
self.proxies.append(proxy_url)
步骤 2. 爬虫脚本 (scraper.py):
import asyncio
from crawl4ai import AsyncWebCrawler
from crawl4ai.async_configs import BrowserConfig
from proxy_module import ProxyManager
# 切换类型 (residential, mobile, datacenter)
PROXY_TYPE = "residential"
# 切换协议 (http 或 socks5 — socks5 仅限无验证模式!)
PROXY_PROTOCOL = "http" # 建议用于验证;对于 SOCKS5 请删除文件中的 login:password
# 初始化管理器
proxy_manager = ProxyManager(proxy_type=PROXY_TYPE, protocol=PROXY_PROTOCOL, rotate=True)
async def main():
try:
proxy_config = proxy_manager.get_proxy_config()
browser_config = BrowserConfig(proxy_config=proxy_config)
async with AsyncWebCrawler(verbose=True, config=browser_config) as crawler:
current_proxy = proxy_manager.get_proxy()
print(f"🚀 正在通过 {PROXY_PROTOCOL.upper() 代理启动...")
print(f"代理地址: {current_proxy}")
result = await crawler.arun(
url="https://ipinfo.io/json",
bypass_cache=True
)
if result.success:
print("\n✅ 成功!响应内容:")
print(result.markdown)
else:
print(f"\n❌ 错误: {result.error_message}")
except Exception as e:
print(f"❌ 错误: {str(e)}")
if __name__ == "__main__":
asyncio.run(main())
步骤 3. 运行:
python scraper.py
- 对于 SOCKS5:将 PROXY_PROTOCOL 设置为 "socks5" 并从文件中删除验证信息(仅保留 host:port)。如果需要验证 — 请使用 HTTP 代理。
第 4 部分。高级场景与问题解决
自动轮换 (适用于动态住宅和移动代理):
无需额外代码 — CyberYozh App 网关会自动轮换 IP。只需在循环中调用 crawler.arun:
for url in urls_list:
proxy_config = proxy_manager.get_proxy_config() # 用于轮换的新配置
browser_config = BrowserConfig(proxy_config=proxy_config)
# 如有必要,请使用新配置重新初始化爬虫
result = await crawler.arun(url=url, bypass_cache=True)
静态代理手动轮换 (住宅/数据中心):
在 proxies_residential.txt 或 proxies_datacenter.txt 文件中添加多行内容并设置 rotate=True。或者使用链接或 API 请求来更换 IP。
带间隔的大规模抓取:
添加延迟以模拟真实人类行为:
import time
time.sleep(random.uniform(1, 5)) # 请求前随机暂停 1-5 秒
💡 提示:某些网站可能会使用基于验证码(CAPTCHA)的检查机制来防止自动化访问。如果您的工作流程中出现此类问题,您可以集成第三方验证码处理服务,例如 CapSolver。它支持 reCAPTCHA v2/v3、Cloudflare Turnstile、Challenge、AWS WAF 等。请确保您的操作符合目标网站的服务条款及相关法律。
问题解决:
- 连接错误: 检查文件中的格式 (login:password@host:port)。在浏览器中测试代理。
- 尽管使用了代理仍被封锁: 增加暂停时间或更换代理类型(针对严密防护的网站改用移动代理)。在 Crawl4AI 中开启隐身模式:在 BrowserConfig 中设置 browser_type="undetected"。
- Playwright 错误: 确保已执行 playwright install。如果设置 headless=False,浏览器将以可视模式打开以便调试。
- SOCKS5 身份验证错误: Playwright 不支持 — 请改用 HTTP 代理。
- Asyncio 异常: 可以忽略;这是 Windows 特有的现象,不影响运行。
- 日志记录: 在 Crawl4AI 中设置 verbose=True 以获取详细日志。
结论
Crawl4AI + CyberYozh App 代理 — 是实现无阻碍数据采集的理想搭档。请选择:
- 动态住宅代理:用于大规模数据集(Amazon/Google)。
- 移动共享代理:用于社交网络及高防护网站。
- 静态住宅代理:用于需要保持会话的任务。
- 静态数据中心代理:用于简单、快速的数据采集。
前往 CyberYozh App 目录,选择合适的代理,配置 Crawl4AI 并扩展您的 AI 爬虫规模。
补充文档:Crawl4AI GitHub