Configuración del proxy en Crawl4AI
Crawl4AI — es una potente herramienta de código abierto para el web scraping, diseñada para extraer datos limpios de páginas web aptos para el entrenamiento de modelos de IA y LLM. Es rápido, flexible y capaz de eludir las protecciones básicas de los sitios, como los sistemas anti-bot sencillos. Para protecciones más complejas, incluyendo CAPTCHA, se recomienda la integración con servicios de terceros (ver Parte 4).
Sin embargo, al realizar un scraping a gran escala (por ejemplo, 10,000 páginas), su dirección IP local será bloqueada rápidamente. Para evitar esto y garantizar un flujo continuo de datos para sus modelos de IA, es necesaria una infraestructura de proxy fiable. En esta guía, analizaremos cómo elegir el tipo de proxy adecuado de CyberYozh App para su tarea e integrarlo en Crawl4AI.
🛑 Información crítica sobre protocolos (HTTP vs SOCKS5): La biblioteca Playwright (sobre la que funciona Crawl4AI) no admite proxies SOCKS5 con autorización (login:password). Dado que todos los proxies en CyberYozh App funcionan solo con autorización por seguridad, para trabajar con Crawl4AI debe utilizar el protocolo HTTP. Este admite plenamente la autorización y garantiza un funcionamiento estable.
Características clave de la integración: El proxy es un módulo independiente (proxy_module.py) para mayor modularidad. Los datos se almacenan en archivos de texto (por tipo: residenciales, móviles, datacenter). El cambio de tipo/protocolo se realiza en una o dos líneas en el script principal.
Parte 1. Elección del proxy: ¿Qué tipo es el adecuado para su conjunto de datos?
Crawl4AI es versátil, pero su eficacia depende del "combustible": el conjunto de direcciones IP. En CyberYozh App están disponibles diferentes tipos de proxies, cada uno optimizado para escenarios específicos de scraping. La elección depende del nivel de protección del sitio, el volumen de datos y la necesidad de rotación. Todos los tipos son compatibles tanto con HTTP como con SOCKS5.
- Residenciales Rotativos (Residential Rotating) — La opción nº 1 para el scraping masivo
- Esencia: Un grupo de millones de direcciones IP domésticas reales. Rotación automática: nueva IP por enlace o por solicitud de API.
- Ideal para Crawl4AI: Grandes conjuntos de datos de marketplaces (Amazon, Wildberries), motores de búsqueda (Google, Yandex).
- Por qué: Alta confianza, minimiza los bloqueos. Admiten 3 tipos de sesiones (IP aleatoria, Corta, Larga de hasta 6 horas).
- Residenciales Estáticos (Residential Static / ISP)
- Esencia: Direcciones IP domésticas fijas durante el periodo de alquiler.
- Ideal para Crawl4AI: Sitios con autorización (áreas personales).
- Por qué: Estabilidad de las sesiones.
- Puertos Móviles Dedicados (Mobile Dedicated)
- Esencia: Un módem privado con una tarjeta SIM real, dedicado personalmente a usted.
- Ideal para Crawl4AI: Tareas complejas, sitios con protección anti-bot estricta, emulación del comportamiento de un usuario real de dispositivo móvil.
- Por qué: Máxima confianza por parte de los sitios. Recomendado para los casos más difíciles.
- Proxies Móviles Compartidos (Mobile Shared)
- Esencia: IP de 4G/5G, canal compartido en modo privado.
- Ideal para Crawl4AI: Redes sociales (Instagram, TikTok) o sitios con protección (Cloudflare).
- Por qué: Alta confianza para el tráfico móvil.
- Proxies Datacenter Dedicados (Datacenter)
- Esencia: Direcciones IP de servidores, rápidas y económicas.
- Ideal para Crawl4AI: Fuentes abiertas sin protección.
- Por qué: Máxima velocidad.
Consejo de integración: Para un enfoque mixto, combine los tipos.
Parte 2. Preparación de datos e instalación
Prepare los datos de CyberYozh App:
Tras comprar el proxy, copie los datos:
- Host (IP): 51.77.190.247
- Port: 5959
- Login: user123
- Password: pass123
Formato de la cadena de conexión: Crawl4AI (al igual que la biblioteca Playwright en la que se basa) acepta el proxy en un formato de cadena única: http://login:password@ip:port
Ejemplo: http://user123:pass123@51.77.190.247:5959
Gestión de Proxies Residenciales Rotativos
Para los Proxies Residenciales Rotativos en CyberYozh App, está disponible una configuración flexible de la sesión directamente a través del login (username). Esto es fundamental para la lógica de su scraper.
Las credenciales se pueden generar en el área personal, pulsando el botón “Generar credenciales” en la tarjeta del paquete. Formatos de salida disponibles: IP:PORT:USERNAME:PASSWORD o enlace para cURL.
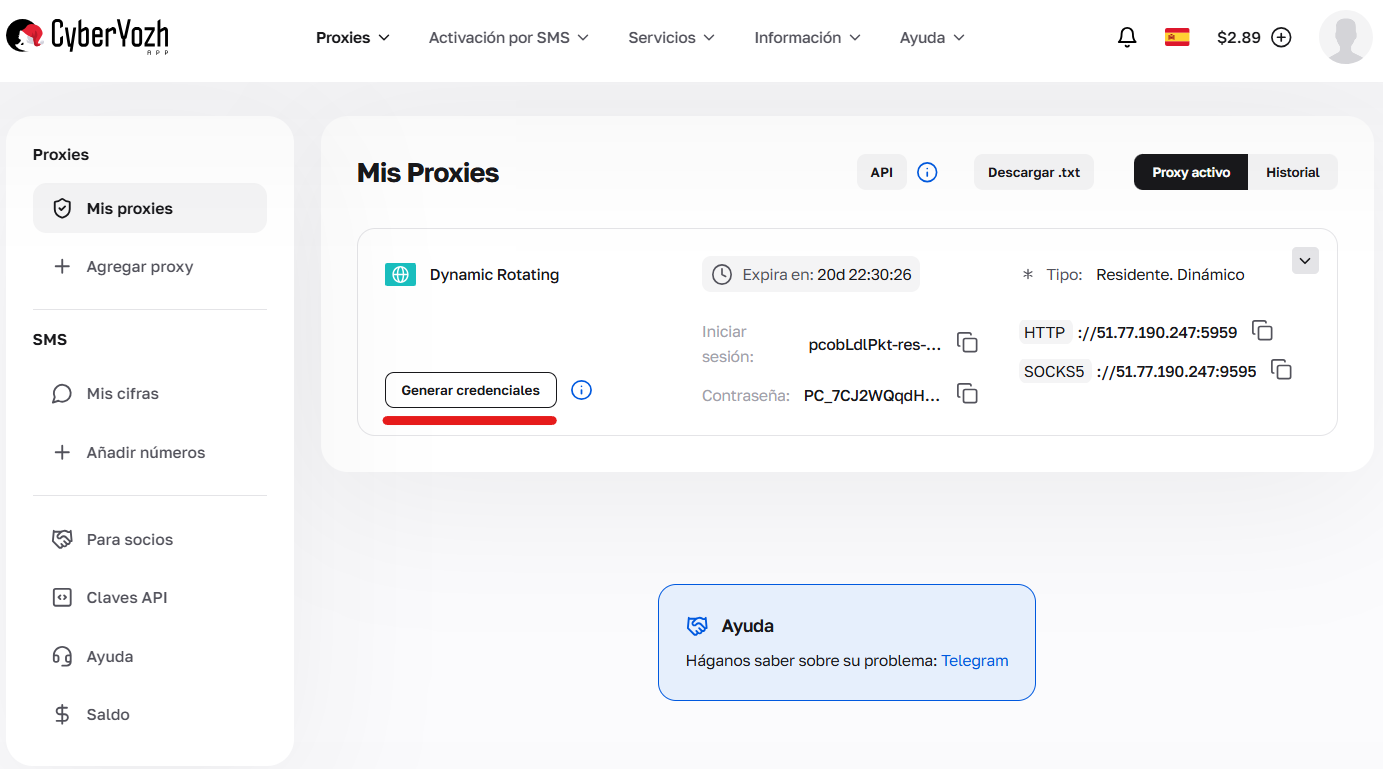
Fig. 1. Transición a la interfaz de creación de configuraciones y parámetros de conexión (generador de credenciales).
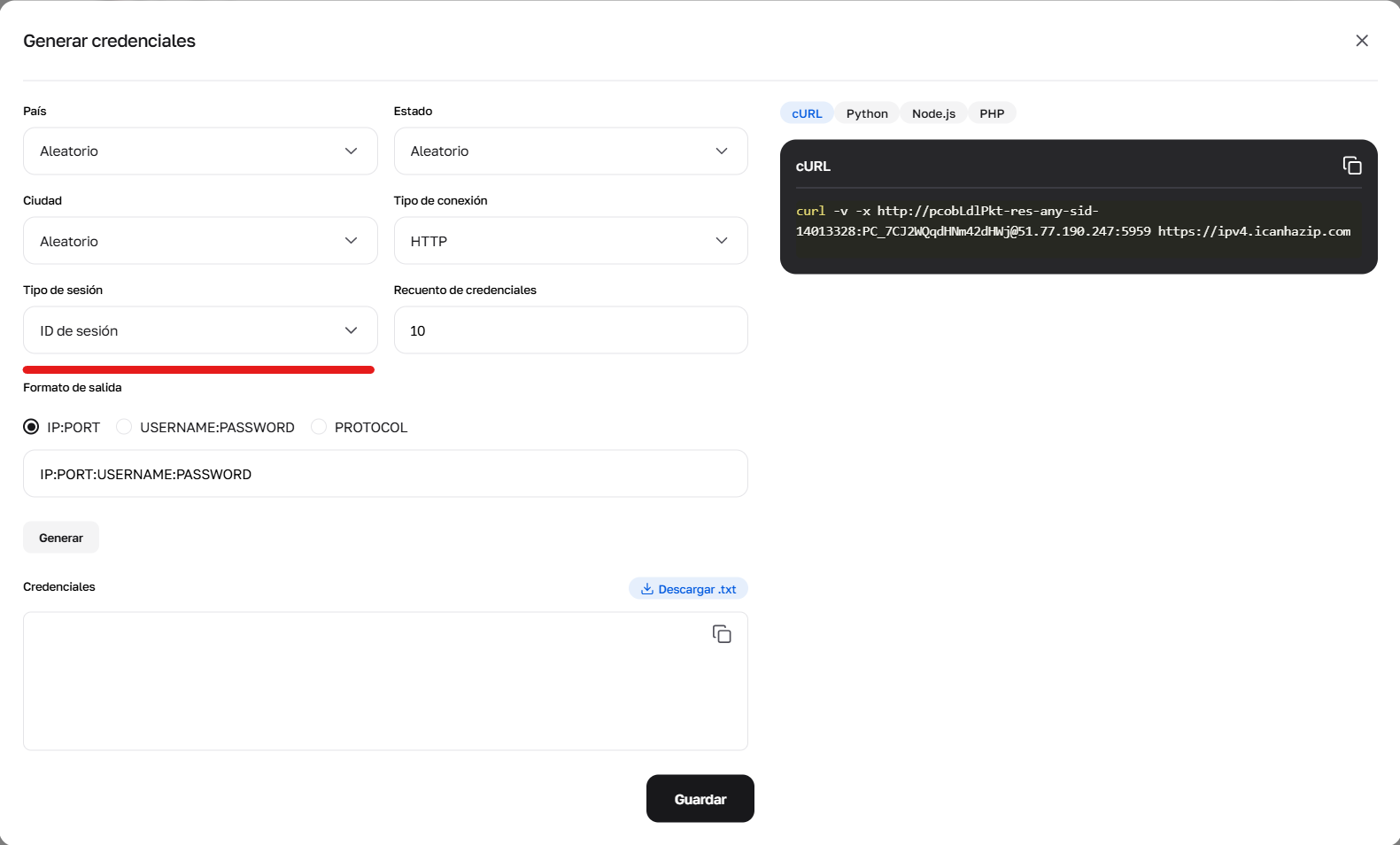
Fig. 2. Uso del generador para configurar el parámetro sid, responsable de la creación de nuevas sesiones únicas.
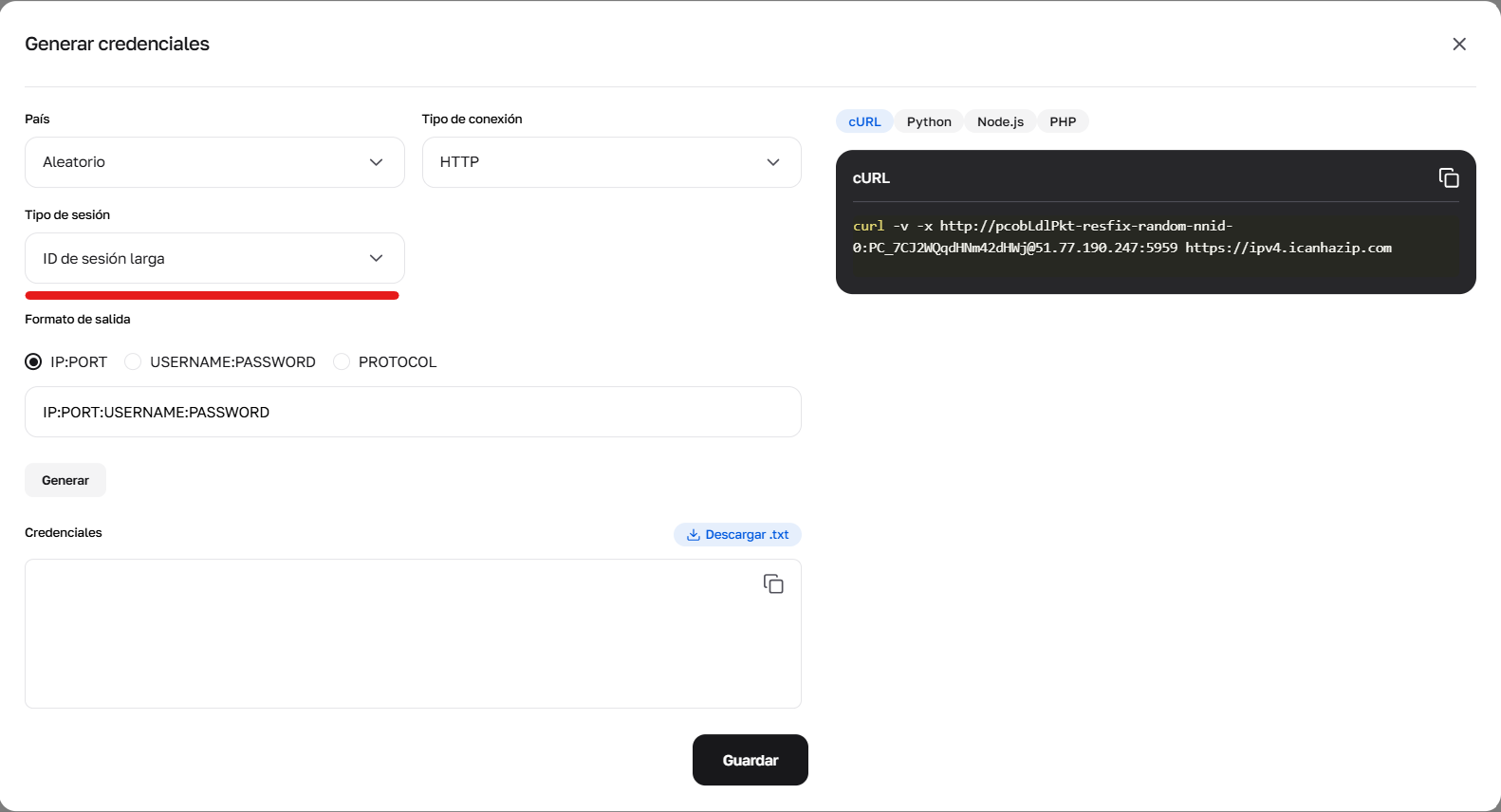
Fig. 3. Configuración de parámetros para la formación de credenciales utilizando sesiones largas (Sticky).
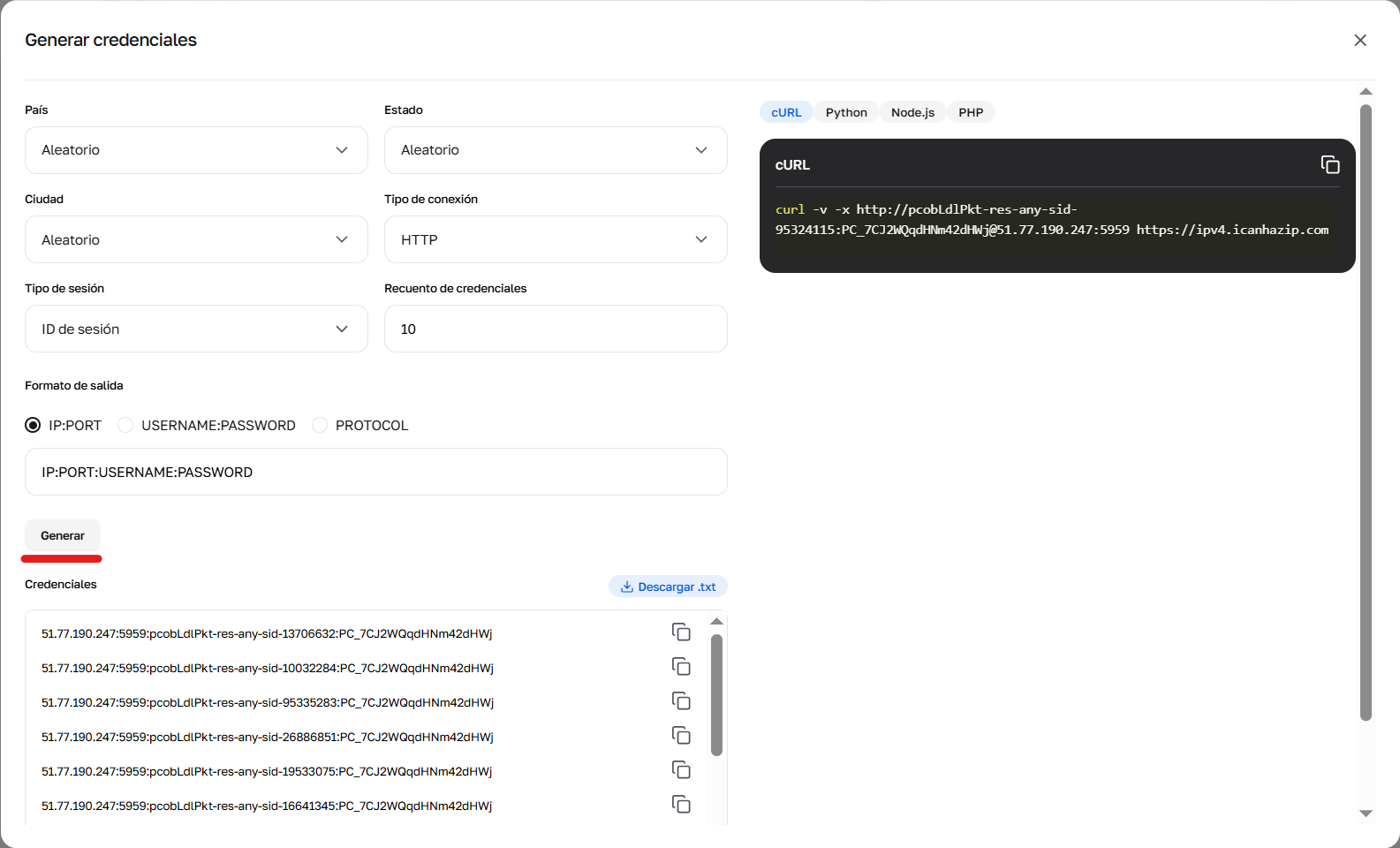
Fig. 4. Resultado del funcionamiento del generador de credenciales.
Tipos de sesiones y cómo definirlas:
1. IP aleatoria (Random IP) — una nueva IP para cada solicitud Utilice el prefijo -res-any. Ejemplo de login: user-res-any Cuándo es necesario: Scraping normal donde no se necesita mantener el estado entre páginas.
2. Sesión corta (hasta 1 minuto) Permite mantener la IP por un tiempo breve (por ejemplo, para pasar un captcha y cargar la página). Utilice el prefijo -sid-NUMEROALEATORIO.
Formato: user-res-any-sid-47551677 (donde 47551677 es cualquier número aleatorio generado por usted).
Geo: En las sesiones cortas se puede elegir País, Región y Ciudad (ejemplo: -res_sc-us_georgia_macon-sid-54683597).
3. Sesión larga persistente (hasta 6 horas) Esta es una sesión Sticky, que mantiene una misma IP hasta 6 horas. Ideal para el parseo profundo de un sitio.
Cómo obtenerla: Opción A (Simple): Generar una cadena lista con "Sesión larga" en el generador de credenciales en su área personal. Opción B (Avanzada/API): Es necesario realizar 2 pasos. Hacer una solicitud cURL con el prefijo -resfix- (por ejemplo, user-resfix-us-nnid-0). En el encabezado de la respuesta X-NN-LLS obtener un token (por ejemplo, 9d016e26...). Sustituir este token en lugar de 0 en el login: user-resfix-us-nnid-9d016e26....
Gestión de proxies móviles en el área personal
El trabajo con proxies móviles tiene una característica importante: para el cambio de IP se utiliza un enlace API. Asegúrese de encontrarlo en la tarjeta del paquete comprado; este es el URL que debe insertar en su software o script para configurar la rotación automática.
Fig. 5. Ubicación del enlace para la rotación automática.
Además, en CyberYozh App se prevé un modo manual. Si necesita cambiar la dirección IP ahora mismo sin recurrir a scripts, simplemente pulse el botón de cambio de IP en el panel de control; la dirección se actualizará instantáneamente.
Fig. 6. Botón para el cambio manual forzado.
Cree los archivos en el directorio del proyecto:
proxies_residential.txt:
user123:pass123@51.77.190.247:5959 Añada más proxies para la rotación.
proxies_mobile.txt y proxies_datacenter.txt de forma análoga. * Formato: login:password@host:port para auth (solo con HTTP).
Instalación:
pip install crawl4ai playwright
playwright install
Compruebe la instalación: python -m crawl4ai --version. Utilice venv si es necesario.
Parte 3. Integración de proxy en Crawl4AI (Python) como un módulo independiente
El módulo proxy_module.py carga los proxies desde archivos, añade el protocolo ("http" o "socks5") y admite la rotación.
Paso 1. Módulo de proxy (proxy_module.py):
import random
import os
class ProxyManager:
def __init__(self, proxy_type="residential", protocol="http", rotate=True):
"""
Inicialización del gestor de proxy.
:param proxy_type: Tipo ('residential', 'mobile', 'datacenter')
:param protocol: Protocolo ('http' o 'socks5') — ¡socks5 solo sin auth!
:param rotate: Activar/desactivar rotación
"""
self.proxy_type = proxy_type.lower()
self.protocol = protocol.lower()
self.rotate = rotate
self.proxies = self._load_proxies() # Cargamos desde el archivo
if self.protocol == "socks5" and self.proxies and '@' in self.proxies[0]: # Verificación de auth
raise ValueError("¡SOCKS5 no admite autenticación en Playwright! Elimine login:password del archivo.")
self.current_proxy = None
def _load_proxies(self):
"""Carga proxies desde el archivo."""
file_map = {
"residential": "proxies_residential.txt",
"mobile": "proxies_mobile.txt",
"datacenter": "proxies_datacenter.txt"
}
file_name = file_map.get(self.proxy_type)
if not file_name:
raise ValueError(f"Tipo desconocido: {self.proxy_type.")
file_path = os.path.join(os.path.dirname(__file__), file_name)
if not os.path.exists(file_path):
raise FileNotFoundError(f"El archivo {file_name no fue encontrado.")
with open(file_path, 'r') as f:
lines = f.read().strip().splitlines()
# Añadimos el protocolo: protocol://line (line = user:pass@host:port o host:port)
proxies = [f"{self.protocol://{line.strip()}" for line in lines if line.strip()]
if not proxies:
raise ValueError(f"El archivo {file_name} está vacío.")
return proxies
def get_proxy(self):
"""Devuelve un proxy."""
if not self.proxies:
raise ValueError("¡No hay proxies!")
if self.rotate:
self.current_proxy = random.choice(self.proxies)
else:
self.current_proxy = self.proxies[0]
return self.current_proxy
def get_proxy_config(self):
"""Devuelve ProxyConfig para Crawl4AI."""
if not self.current_proxy:
self.get_proxy()
# Dividimos: protocol://user:pass@host:port o protocol://host:port
if '@' in self.current_proxy:
parts = self.current_proxy.split('@')
auth = parts[0].split('//')[1] # user:pass
host_port = parts[1] # host:port
user, password = auth.split(':')
else:
host_port = self.current_proxy.split('//')[1] # host:port para no-auth
user, password = None, None
from crawl4ai.async_configs import ProxyConfig
return ProxyConfig(
server="{self.protocol://{host_port",
username=,
=)
def add_proxy(self, ):
self..()
Paso 2. Script del scraper (scraper.py):
import asyncio
from crawl4ai import AsyncWebCrawler
from crawl4ai.async_configs import BrowserConfig
from proxy_module import ProxyManager
# Cambio de tipo (residential, mobile, datacenter)
PROXY_TYPE = "residential"
# Cambio de protocolo (http o socks5 — ¡socks5 solo sin auth!)
PROXY_PROTOCOL = "http" # Recomendado para auth; para SOCKS5 elimine login:password del archivo
# Inicializamos el gestor
proxy_manager = ProxyManager(=, =, =True)
async def main():
try:
= ()
= (=)
async with (=True, =) as :
= ()
print("🚀 Lanzando a través de {() proxy...")
print("Proxy: {")
= await (
="https://ipinfo.io/json",
=True
)
if :
print("\n✅ ¡Éxito! Respuesta:")
print()
else:
print("\n❌ Error: {Paso 3. Ejecución:
python scraper.py
- Para SOCKS5: Establezca PROXY_PROTOCOL = "socks5" y elimine auth de los archivos (solo host:port). Si necesita auth, utilice "http".
Parte 4. Escenarios avanzados y resolución de problemas
Rotación automática (para residenciales rotativos y móviles):
No es necesario código adicional; la pasarela de CyberYozh App rota la IP por sí sola. Simplemente llame a crawler.arun en un bucle:
for in :
= () # Nueva configuración para la rotación
= (=)
# Reinicialice el crawler con la nueva config si es necesario
= await (=, =True)
Rotación manual para estáticos (residenciales/datacenter):
Añada varias líneas al archivo proxies_residential.txt o proxies_datacenter.txt y utilice rotate=True. O bien, utilice el cambio de IP por enlace o solicitud API.
Scraping masivo con pausas:
Añada retardos para imitar el comportamiento humano:
import time
((, )) # Pausa de 1 a 5 seg antes de la solicitud
💡 Consejo: algunos sitios web pueden utilizar mecanismos de verificación basados en CAPTCHA para evitar el acceso automatizado. Si surgen tales problemas en su flujo de trabajo, puede integrar un servicio externo de resolución de CAPTCHA, como CapSolver. Es compatible con reCAPTCHA v2/v3, Cloudflare Turnstile, Challenge, AWS WAF y otros. Asegúrese de que su uso cumpla con los términos de servicio del sitio web de destino y las leyes aplicables.
Resolución de problemas:
- Error de conexión: Compruebe el formato en los archivos (login:password@host:port). Pruebe el proxy en un navegador.
- Bloqueo a pesar del proxy: Aumente las pausas o cambie el tipo (a móviles para sitios estrictos). Añada el modo stealth en Crawl4AI: browser_type="undetected" en BrowserConfig.
- Errores de Playwright: Asegúrese de que se haya ejecutado playwright install. Si headless=False, el navegador se abrirá visiblemente para la depuración.
- Error de auth SOCKS5: Playwright no lo admite; utilice proxies HTTP.
- Excepciones de Asyncio: Ignórelas; es una particularidad de Windows que no afecta.
- Registro (Logging): Active verbose=True en Crawl4AI para obtener registros detallados.
Conclusión
Crawl4AI + proxies de CyberYozh App — el dúo ideal para recopilar datos sin bloqueos. Elija:
- Residenciales Rotativos para conjuntos de datos masivos (Amazon/Google).
- Móviles Compartidos (Shared) para redes sociales y sitios protegidos.
- Residenciales Estáticos para tareas de sesión.
- Datacenter Estáticos para recopilaciones de datos sencillas y rápidas.
Diríjase al catálogo de CyberYozh App, elija los proxies adecuados, configure Crawl4AI y escale su scraping de IA.
Documentación adicional: Crawl4AI GitHub