Playwright代理设置
Playwright 是一个现代化的网页抓取和自动化框架,支持多种编程语言,并与 CyberYozh 代理良好集成,以提供额外的安全性和会话稳定性。在此,了解如何设置 Playwright 并确保您的工作顺利完成。
准备工作:选择与 Playwright 配合使用的代理
在配置 Playwright 代理集成之前,您必须构建正确的抓取/自动化基础设施。您的代理类型决定了信任级别、会话稳定性、速度以及平台如何感知您的流量。
移动代理:社交数据和精准地理定位
移动代理 在所有代理类型中具有最高的信任率,使其成为社交媒体抓取和移动优先应用程序的推荐选择,例如 Instagram、 TikTok和 Snapchat。
CyberYozh 移动代理为精准地理定位、指纹设置和无限流量提供高度定制化;当您需要 Playwright 模拟真实移动用户时,这是理想选择。
住宅代理:通用数据抓取和自动化
住宅代理根据您的使用场景分为两种类型:
静态住宅代理 提供来自特定国家的固定住宅 IP,被平台视为普通家庭互联网用户。它们非常适合与账户关联的工作流程。
轮换住宅代理 使用覆盖 100 多个国家的 5000 万以上 IP 池,按请求或按会话轮换地址。它们最适合使用 Playwright 进行批量自动化和大规模网页抓取
选择静态住宅 IP 进行长期账户管理,采用 1 IP = 1 账户的方案,而轮换 IP 则适用于所有批量网络活动,并根据每个具体使用场景采用适当的 IP 轮换策略 。
数据中心代理:开放数据库和应用测试
数据中心代理 提供最快的连接速度,但与非住宅、类似机器人的流量相关联。它们适用于抓取开放数据库、测试 API 以及平台应用最少机器人检测的高速任务,但在 Reddit 或 LinkedIn等社交平台上可能会很快受到限制。
附加工具:IP 检查器确保质量
CyberYozh 提供 IP 检查器 ,可针对多个欺诈数据库扫描每个 IP 地址,返回信任评分和完整历史记录。在 Playwright 会话中轮换到新 IP 之前,通过检查器运行它以确认不会触发封禁。
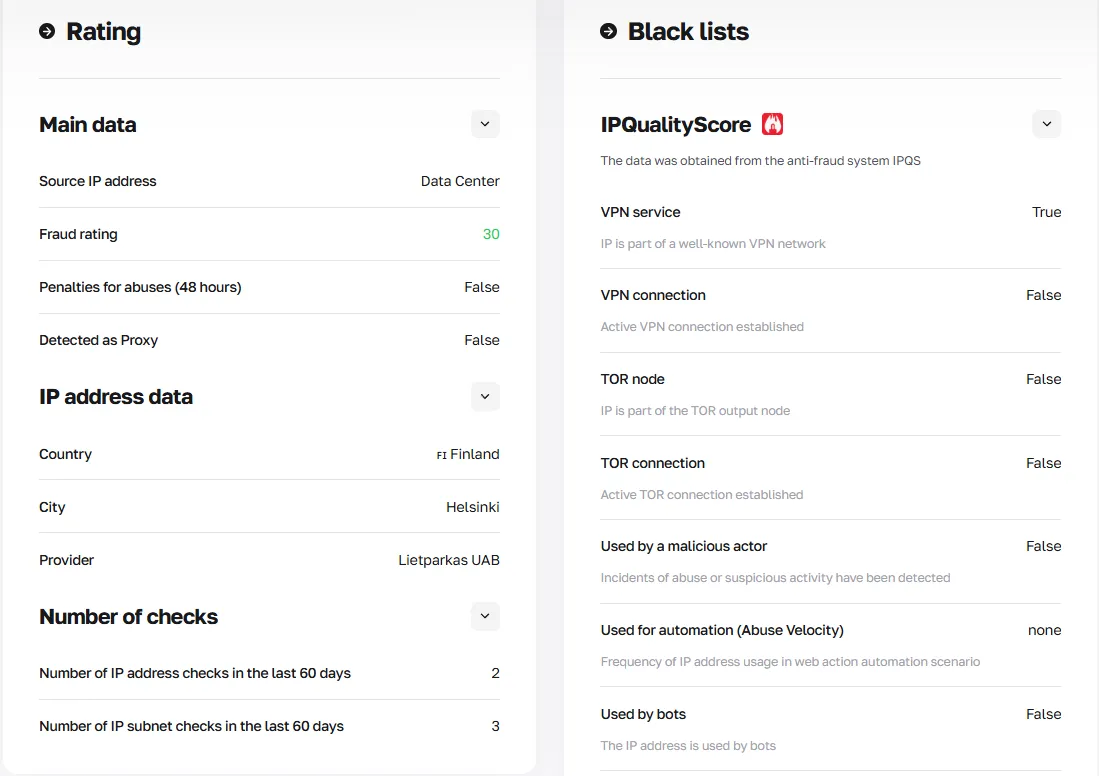
获取 CyberYozh API 访问权限以自动化 IP 轮换,并在轮换前检查每个传入的 IP 地址,确保其质量。
从 Playwright 安装开始:选择编程语言
Playwright 支持四种编程语言。在开始安装 Playwright 并配置代理之前,请选择适合您技术栈的语言。本指南使用 Python,因为它是代理工作流中最常用的选择,但下表和简要说明涵盖了所有四种选项。
编程语言 | 主要区别 | 主要用途 | 何时选择 |
Node.js (JS/TS) | Playwright 的默认语言;开箱即用的 TypeScript 支持;拥有最大的社区和文档资源 | 端到端测试、浏览器自动化、前端 CI/CD | 您的团队使用 JS/TS,或者您需要最成熟的工具链 |
Python | 在爬虫/机器学习领域使用最广泛;通过 asyncio支持异步;可与 Requests、Scrapy 集成 | 网页爬虫、数据管道、代理自动化、机器学习数据采集 | 您需要大量使用代理的爬虫任务或数据科学集成 |
.NET (C#) | 通过 NuGet 分发;强类型,适合企业级 QA | 企业测试自动化、.NET 应用程序 | 您的组织使用 .NET 技术栈 |
Java | 通过 Maven/Gradle 分发;集成 JUnit | Java 企业应用、Android 相关测试 | 您的项目基于 Java 或需要 JVM 生态系统 |
Node.js
Playwright 的默认语言,文档最完善。原生支持 TypeScript:使用 npm安装 Playwright,无需额外配置。
npm init playwright@latestPython
用于 Playwright 代理任务、爬虫和数据自动化的首选语言。需要 Python 3.8+ 版本,通常通过 PyPI(pip)安装。
pip install playwright
playwright install.NET (C#)
作为 NuGet 包分发。需要 PowerShell(pwsh)来运行浏览器安装步骤。
dotnet new console -n PlaywrightDemo
cd PlaywrightDemo
dotnet add package Microsoft.Playwright
dotnet build
pwsh bin/Debug/netX/playwright.ps1 install Java
作为 Maven(mvn)模块分发。在 Maven 的 pom.xml 中添加依赖项,浏览器会在首次编译时自动下载。
<dependency>
<groupId>com.microsoft.playwright</groupId>
<artifactId>playwright</artifactId>
<version>1.59.0</version>
</dependency> 然后运行命令:
mvn compile exec:java -D exec.mainClass="org.example.App"使用 Python 设置 Playwright 代理
在这里,让我们探索如何使用 CyberYozh 代理部署通用的 Playwright 抓取会话。虽然 Playwright 的默认语言是 Node.js/TypeScript,但我们将在示例中使用 Python ,因为 Playwright 与 Python 的组合被广泛用于网页自动化、抓取和其他与代理相关的任务。如果您需要使用 TypeScript 或有需要 C# 或 Java 的特定用例,只需查阅相应的 Playwright 文档版本即可;调整代码非常容易。
Playwright 代理服务器 是一个网络中介,它通过不同的 IP 地址转发您的浏览器请求。Playwright 在浏览器启动或上下文级别直接传递代理配置,将所有流量路由通过指定的服务器。
1. 为您的任务获取代理
登录您的 CyberYozh 账户,导航至 我的代理,并选择适合您任务的代理类型(移动代理、住宅静态代理、住宅轮换代理、数据中心代理)。
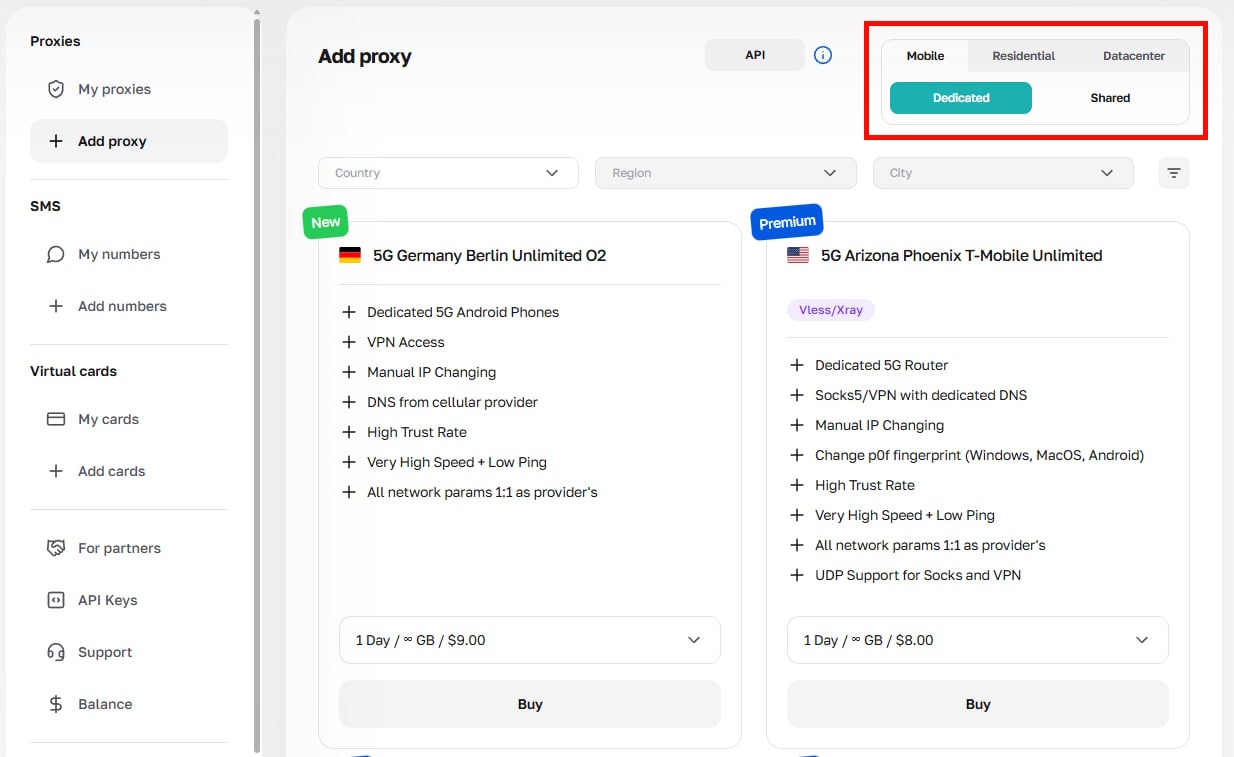
购买后,打开代理卡片,点击 生成凭证,选择您的轮换模式(随机 IP、短会话或长会话),然后导航至主机、端口、用户名和密码。
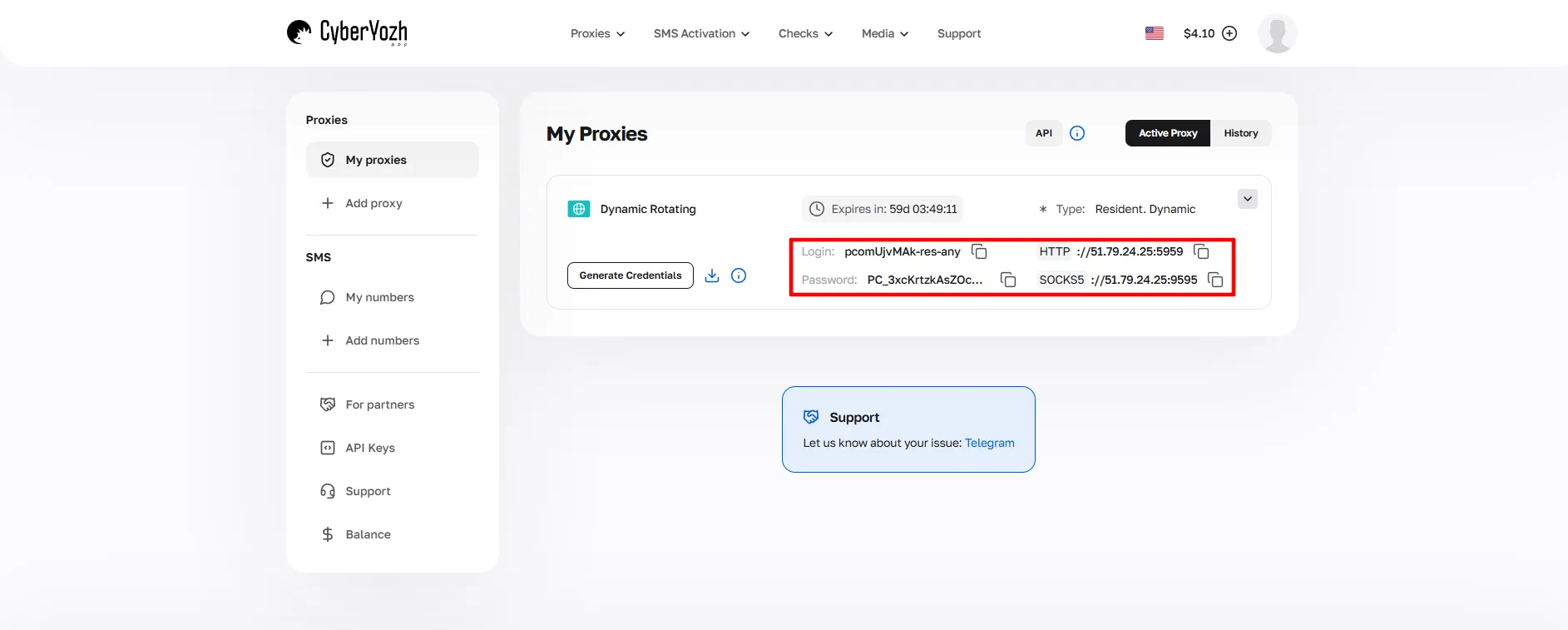
这些凭证将在整个设置过程中使用。
2. 下载并安装 Playwright
通过 PyPI 安装 Playwright 库及其浏览器二进制文件:
pip install playwright
playwright install这将下载 Chromium、Firefox 和 WebKit 二进制文件。对于抓取任务,Chromium 是标准选择。
3. 组织项目结构
创建一个专用的项目文件夹(例如 scraper/)。将凭证与代码分开保存,并为抓取的数据定义清晰的输出路径:
-.env 文档用于存放代理凭证(始终添加到 .gitignore)
-scraper.py 作为主要的 Playwright 脚本
-requirements.txt 用于依赖项
output/ 文件夹用于存放抓取的数据(CSV/JSON)
4. 将代理配置添加到 .env 文件
在 VS Code 或任何编辑器中打开您的 .env 文件,并复制粘贴您的 CyberYozh 凭证。始终将 .env 添加到您的 .gitignore 中,以防止凭证泄露到版本控制仓库。
HTTP_PROXY=http://username:password@proxy-server-ip:host
SOCKS5_PROXY=socks5://username:password@proxy-server-ip:host
对于 Playwright SOCKS5 代理配置,使用 socks5:// 方案。对于标准的 Playwright HTTP 代理使用,使用 http:// 协议。请确保包含 CyberYozh 仪表板中的正确端口。如果使用 CyberYozh API,还必须在此处指定您的 API 密钥。
CYBERYOZH_API_KEY=Your_API_URL_Key
5. 创建抓取/自动化脚本
使用 Playwright 创建 Python 测试文件。其结构大致如下:
创建带有代理设置的浏览器和上下文实体
通过 CyberYozh API 设置自动轮换和 IP 检查
访问目标网站并通过 Requests 库执行抓取
设置错误处理
指定抓取数据的输出文件夹
下面的脚本实现了 Python 中完整的 Playwright 代理设置:浏览器实体、带 Playwright 代理身份验证的上下文实体、通过 CyberYozh API 的自动 IP 轮换、请求执行、错误处理和文件输出。
import asyncio
import os
import json
import requests
from dotenv import load_dotenv
from playwright.async_api import async_playwright
load_dotenv()
PROXY_URL = os.getenv("HTTP_PROXY") # or SOCKS5, from the .env document
CYBERYOZH_API_KEY = os.getenv("CYBERYOZH_API_KEY") # API key from the .env document
TARGET_URL = "https://httpbin.org/ip" # the website to scrape; here is the test one
OUTPUT_FILE = "output/results.json" # output folder
def check_ip_quality(ip: str) -> bool:
"""Use CyberYozh IP Checker API to verify trust score before rotating."""
try:
response = requests.get(
f"https://app.cyberyozh.com/api/v1/ip-check?ip={ip}",
headers={"Authorization": f"Bearer {CYBERYOZH_API_KEY}"},
timeout=5
)
score = response.json().get("fraud_score", 100)
return score < 50 # Accept IPs with fraud score below 50
except Exception:
return True # Allow on API error
async def scrape(proxy_url: str) -> dict:
"""Run a single Playwright scraping session with proxy."""
# Parse proxy credentials for Playwright proxy authentication
from urllib.parse import urlparse
parsed = urlparse(proxy_url)
proxy_config = {
"server": f"{parsed.scheme}://{parsed.hostname}:{parsed.port}",
"username": parsed.username,
"password": parsed.password,
}
async with async_playwright() as p:
# Browser entity (headless to save traffic): launch with proxy server
browser = await p.chromium.launch(headless=True)
# Context entity: proxy settings applied per context
context = await browser.new_context(proxy=proxy_config)
page = await context.new_page()
try:
await page.goto(TARGET_URL, timeout=30000)
content = await page.inner_text("body")
result = json.loads(content)
return {"status": "ok", "ip": result.get("origin")}
except Exception as e:
return {"status": "error", "error": str(e)}
finally:
await context.close()
await browser.close()
async def main():
results = []
for i in range(5):
print(f"Request {i+1}: using proxy {PROXY_URL}")
data = await scrape(PROXY_URL)
print(f" → IP: {data.get('ip')} | Status: {data.get('status')}")
results.append(data)
os.makedirs("output", exist_ok=True)
with open(OUTPUT_FILE, "w") as f:
json.dump(results, f, indent=2)
print(f"Results saved to {OUTPUT_FILE}")
asyncio.run(main())另请参阅相关指南: 在 Python 中配置代理轮换。
6. 运行测试并轮换代理
从项目根目录启动爬虫:
python scraper.py验证每个请求记录不同的 IP 地址(确认轮换处于活动状态),并且 output/results.json 文件已填充。使用 CyberYozh API 进行自动轮换和通过 IP 检查器进行自动质量检查:欺诈分数高的代理将在下一个轮换周期之前被拒绝。
另请参阅: 网页抓取自动化指南
总结:将 Playwright 与 CyberYozh 基础设施结合使用
配置好 Playwright 代理并激活 CyberYozh 凭据后,您可以大规模运行多目标抓取、地理定位自动化和账户管理工作流,通过带有欺诈分数验证的干净住宅或移动 IP 路由每个浏览器会话,同时以您选择的格式输出结构化数据。
常见问题
什么是 Playwright 代理服务器,为什么需要它?
Playwright 代理服务器通过中间 IP 地址路由 Playwright 浏览器流量,掩盖您的来源。它可以防止 IP 封禁,绕过地理限制,并使自动化会话看起来像有机用户流量。
如何在 Playwright 中安装代理?
没有单独的安装步骤。运行 Playwright install 后,在 proxy={"server": "...", "username": "...", "password": "..."} 参数处通过 chromium.launch() 或 browser.new_context()传递您的代理凭据。
如何在 Playwright 中使用代理身份验证?
在浏览器启动或上下文创建时,在代理字典内传递 "username" 和 "password" 键。Playwright 原生处理 Playwright 代理身份验证,无需额外的库。
Playwright 支持 SOCKS5 代理吗?
支持。使用 socks5:// 方案中使用正确的端口号。
Playwright 在浏览器级别和上下文级别设置代理有什么区别?
浏览器级别的代理适用于所有上下文和页面。上下文级别的代理允许每个会话使用不同的 Playwright 代理,从而实现多账户工作流,其中每个上下文使用不同的 IP。
哪种 CyberYozh 代理类型最适合基于 Playwright 代理的 Python 网页抓取?
对于批量抓取,使用轮换住宅代理(5000万+ IP 池,按请求轮换);对于社交媒体目标,使用移动代理。数据中心代理适用于需要速度的开放数据库。
如何在 Playwright 中自动轮换代理?
使用 CyberYozh 轮换住宅代理时,轮换是内置的:在用户名中使用 -res-any 后缀,每个新请求都会获得一个新的 IP。无需手动管理 IP 池。
我可以将 Playwright 代理与 Python 的 asyncio 结合用于并发抓取吗?
可以。使用 async_playwright 配合 asyncio。每次 browser.new_context(proxy=...) 调用都可以接收不同的代理配置,从而实现具有不同 IP 的并行会话。
为什么即使使用代理,我的 Playwright 抓取器仍然被封禁?
当 IP 的欺诈评分较高、轮换过于激进或浏览器指纹不一致时,就会发生封禁。使用 CyberYozh IP Checker 验证 IP 质量,并考虑将代理与反检测浏览器配对以应对高安全性目标。
如何安全地使用环境变量存储 Playwright 代理凭据?
将凭据存储在 .env 文件中(添加到 .gitignore中),使用 python-dotenv 加载它们,并传递给 chromium.launch()。切勿在源代码中硬编码代理字符串或将其提交到版本控制系统。