Playwright proxy setup
Playwright is a modern web scraping and automation framework that supports multiple programming languages and integrates well with CyberYozh proxies for additional security and session stability. Here, learn how to set up Playwright and ensure that your job is done well.
Preparation: Selecting a proxy to use with Playwright
Before configuring a proxy Playwright integration, you must build the right scraping/automation infrastructure. Your proxy type determines trust level, session stability, speed, and how platforms perceive your traffic.
Mobile proxy: Social data and precise geotargeting
Mobile proxies carry the highest trust rate among all proxy types, making them the recommended choice for social media scraping and mobile-first applications such as Instagram, TikTok, and Snapchat.
CyberYozh mobile proxies offer high customization for precise geotargeting, fingerprint settings, and unlimited traffic; ideal when you need Playwright to emulate a real mobile user.
Residential proxy: General data scraping and automation
Residential proxies are split into two types based on your use case:
Static residential proxies provide a fixed residential IP from a specific country, perceived by platforms as an ordinary home Internet user. They’re ideal for account-linked workflows.
Rotating residential proxies use a pool of 50M+ IPs across 100+ countries, rotating addresses per request or per session. They’re best suited for bulk automation and large-scale web scraping with Playwright
Select static residential IPs for long-term account management, with the scheme of 1 IP = 1 account, while rotating IPs are required for all bulk web activities, with a proper IP rotation strategy based on each specific use case.
Datacenter proxies: Open databases and app testing
Datacenter proxies provide the fastest connection speed, but are associated with non-residential, bot-like traffic. They work well for scraping open databases, testing APIs, and high-speed tasks where platforms apply minimal bot detection, but can be quickly restricted on social platforms like Reddit or LinkedIn.
Additional tool: IP Checker to ensure quality
CyberYozh offers an IP Checker that scans every IP address against multiple fraud databases, returning a trust score and full history. Before rotating to a new IP in your Playwright session, run it through the checker to confirm it won't trigger a ban.
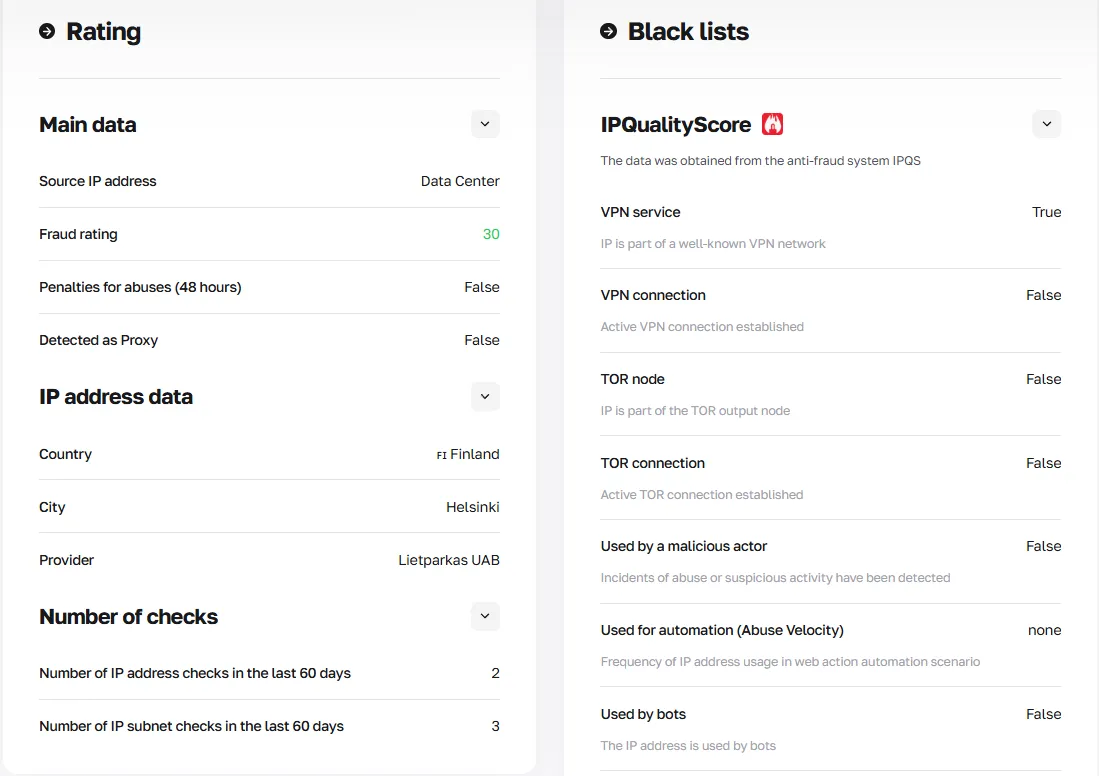
Get the CyberYozh API access to automate IP rotation and check every incoming IP address before rotating, ensuring its quality.
Starting with Playwright installation: Selecting a language
Playwright supports four languages. Before you begin your Playwright installation and proxy configuration, choose the language that fits your stack. This guide uses Python, as the most commonly used choice for proxy workflows, but all four options are covered in the table and short instructions below.
Language | Key Differences | Primary Use Cases | When to Choose |
Node.js (JS/TS) | Default Playwright language; TypeScript support out of the box; largest community and docs | End-to-end testing, browser automation, frontend CI/CD | Your team works in JS/TS, or you need the most mature tooling |
Python | Most widely used in scraping/ML; async via asyncio; integrates with Requests, Scrapy | Web scraping, data pipelines, proxy automation, ML data collection | You need proxy-heavy scraping or data science integration |
.NET (C#) | NuGet distribution; strong typing, good for enterprise QA | Enterprise test automation, .NET applications | Your organization uses a .NET stack |
Java | Maven/Gradle distribution; JUnit integration | Java enterprise apps, Android-adjacent testing | Your project is Java-based or requires JVM ecosystem |
Node.js
The default and most fully documented Playwright language. TypeScript is supported natively: Playwright is installed using npm, with no extra configuration needed.
npm init playwright@latestPython
The go-to language for Playwright proxy tasks, scraping, and data automation. Requires Python 3.8+ and is usually installed via PyPI (pip).
pip install playwright
playwright install.NET (C#)
Distributed as a NuGet package. Requires PowerShell (pwsh) to run the browser install step.
dotnet new console -n PlaywrightDemo
cd PlaywrightDemo
dotnet add package Microsoft.Playwright
dotnet build
pwsh bin/Debug/netX/playwright.ps1 install Java
Distributed as a Maven (mvn) module. Add the dependency to your pom.xml in Maven, and the browsers download automatically on the first compile.
<dependency>
<groupId>com.microsoft.playwright</groupId>
<artifactId>playwright</artifactId>
<version>1.59.0</version>
</dependency> And then run a command:
mvn compile exec:java -D exec.mainClass="org.example.App"Setting a Playwright proxy with Python
Here, let’s explore the generalized Playwright scraping session deployment with CyberYozh proxies. While the default Playwright language is Node.js/TypeScript, we’ll use Python in our example, as Playwright with Python is widely used for web automation, scraping, and other proxy-related tasks. If you need to use TypeScript or have a specific use case requiring C# or Java, just explore the corresponding Playwright docs version; it’s quite easy to adjust the code.
A Playwright proxy server is a network intermediary that relays your browser's requests through a different IP address. Playwright passes the proxy configuration directly at browser launch or context level, routing all traffic through the specified server.
1. Get a proxy for your task
Log in to your CyberYozh account, navigate to My Proxies, and select the proxy type suited to your task (mobile, residential static, residential rotating, datacenter).
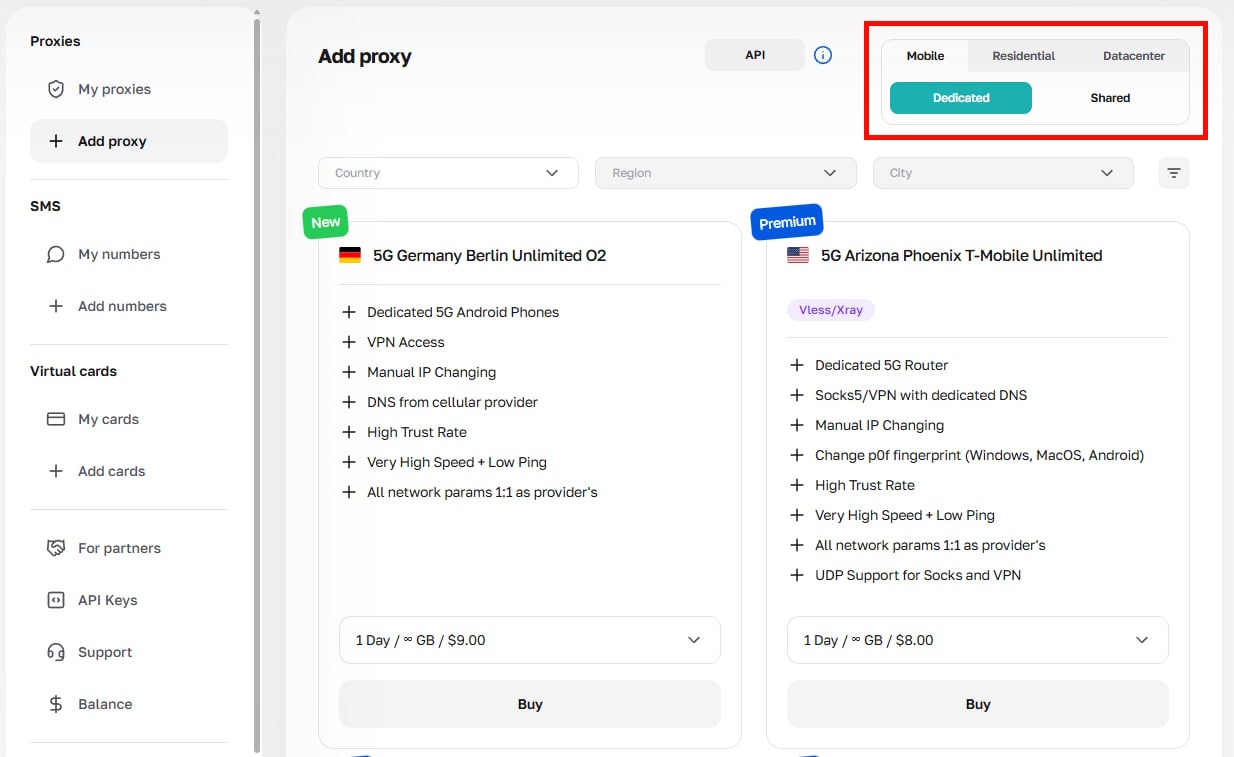
After purchase, open the proxy card, click Generate Credentials, choose your rotation mode (Random IP, Short Session, or Long Session), and navigate to the host, port, username, and password.
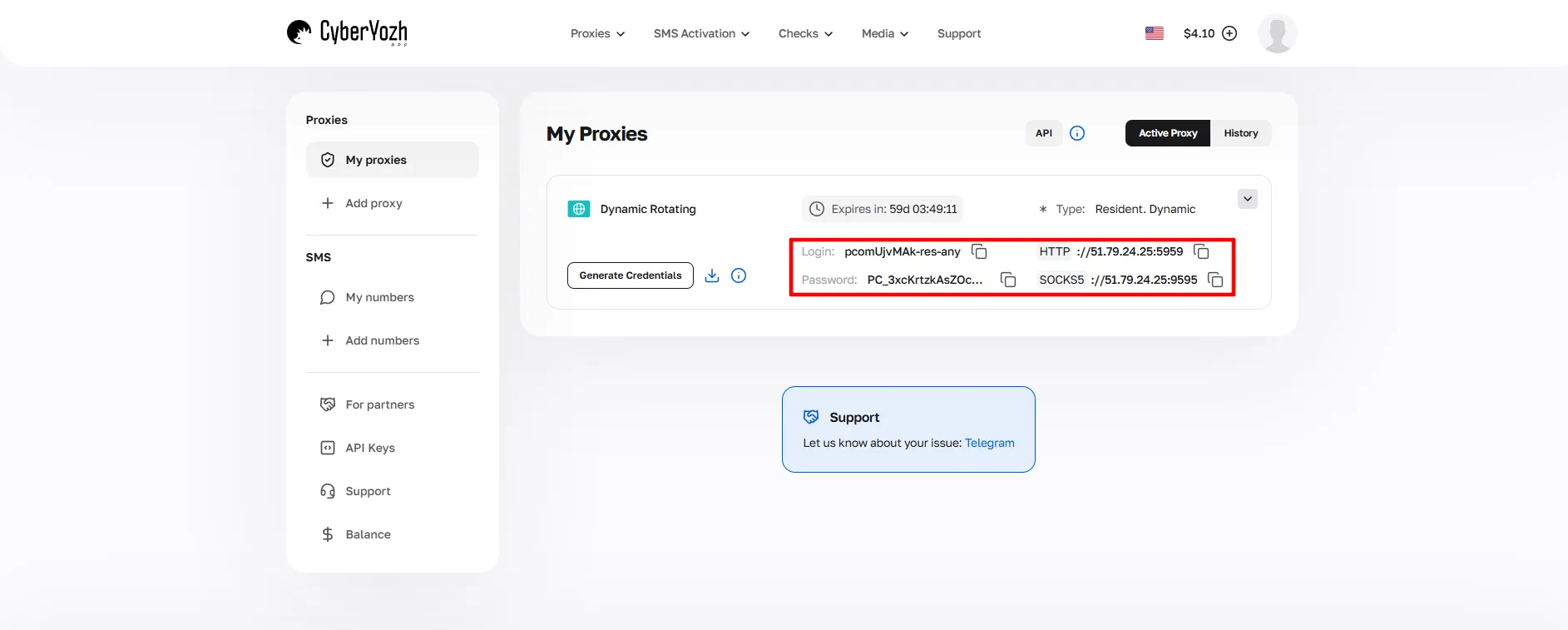
These credentials will be used throughout the setup.
2. Download and install Playwright
Install the Playwright library and its browser binaries via PyPI:
pip install playwright
playwright installThis downloads Chromium, Firefox, and WebKit binaries. For scraping, Chromium is the standard choice.
3. Organize a project structure
Create a dedicated project folder (i.e., scraper/). Keep credentials separate from your code and define a clear output path for scraped data:
-.env document for proxy credentials (always add to .gitignore)
-scraper.py as the main Playwright script
-requirements.txt for dependencies
output/ folder for scraped data (CSV/JSON)
4. Add proxy configuration into .env file
Open your .env file in VS Code or any editor and copy-paste your CyberYozh credentials. Always add .env to your .gitignore to prevent credential leakage to version control repositories.
HTTP_PROXY=http://username:password@proxy-server-ip:host
SOCKS5_PROXY=socks5://username:password@proxy-server-ip:hostFor a Playwright SOCKS5 proxy configuration, use the socks5:// scheme. For standard Playwright HTTP proxy usage, use the http:// scheme. Make sure to include the correct ports from the CyberYozh dashboard. If you use CyberYozh API, your API key must be specified here, too.
CYBERYOZH_API_KEY=Your_API_URL_Key5. Create a scraping/automation script
Create the Python test file using Playwright. It should approximately have the following structure:
Browser and context entity creation with proxy settings
Automated rotation and IP checkup setup via CyberYozh API
Go to the target website and perform scraping via the Requests library
Set up error handling
Specify the output folder for scraped data
The script below implements the full Playwright proxy setup in Python: a browser entity, a context entity with Playwright proxy authentication, automated IP rotation via the CyberYozh API, request execution, error handling, and file output.
Visit CyberYozh's API documentation to explore how exactly you can deploy the API commands for automated CyberYozh service usage
import asyncio
import os
import json
import requests
from dotenv import load_dotenv
from playwright.async_api import async_playwright
load_dotenv()
PROXY_URL = os.getenv("HTTP_PROXY") # or SOCKS5, from the .env document
CYBERYOZH_API_KEY = os.getenv("CYBERYOZH_API_KEY") # API key from the .env document
TARGET_URL = "https://httpbin.org/ip" # the website to scrape; here is the test one
OUTPUT_FILE = "output/results.json" # output folder
def check_ip_quality(ip: str) -> bool:
"""Use CyberYozh IP Checker API to verify trust score before rotating."""
try:
response = requests.get(
f"https://app.cyberyozh.com/api/v1/checkers/socks/",
headers={"Authorization": f"Bearer {CYBERYOZH_API_KEY}"},
timeout=5
)
score = response.json().get("fraud_score", 100)
return score < 50 # Accept IPs with fraud score below 50
except Exception:
return True # Allow on API error
async def scrape(proxy_url: str) -> dict:
"""Run a single Playwright scraping session with proxy."""
# Parse proxy credentials for Playwright proxy authentication
from urllib.parse import urlparse
parsed = urlparse(proxy_url)
proxy_config = {
"server": f"{parsed.scheme}://{parsed.hostname}:{parsed.port}",
"username": parsed.username,
"password": parsed.password,
}
async with async_playwright() as p:
# Browser entity (headless to save traffic): launch with proxy server
browser = await p.chromium.launch(headless=True)
# Context entity: proxy settings applied per context
context = await browser.new_context(proxy=proxy_config)
page = await context.new_page()
try:
await page.goto(TARGET_URL, timeout=30000)
content = await page.inner_text("body")
result = json.loads(content)
return {"status": "ok", "ip": result.get("origin")}
except Exception as e:
return {"status": "error", "error": str(e)}
finally:
await context.close()
await browser.close()
async def main():
results = []
for i in range(5):
print(f"Request {i+1}: using proxy {PROXY_URL}")
data = await scrape(PROXY_URL)
print(f" → IP: {data.get('ip')} | Status: {data.get('status')}")
results.append(data)
os.makedirs("output", exist_ok=True)
with open(OUTPUT_FILE, "w") as f:
json.dump(results, f, indent=2)
print(f"Results saved to {OUTPUT_FILE}")
asyncio.run(main())Also see the related guide: Configuring Proxy Rotation in Python.
6. Run the test and rotate the proxy
Launch the scraper from your project root:
python scraper.pyVerify that each request logs a different IP address (confirming rotation is active) and that the output/results.json file is populated. Use the CyberYozh API for automated rotation and automated quality checkups via the IP Checker: proxies with a high fraud score will be rejected before the next rotation cycle.
See also: Web Scraping Automation Guide
Summary: Using Playwright with CyberYozh infrastructure
With Playwright proxies configured and CyberYozh credentials active, you can run multi-target scraping, geo-targeted automation, and account management workflows at scale, routing every browser session through clean residential or mobile IPs with fraud score validation, while outputting structured data in your chosen format.
FAQ
What is a Playwright proxy server and why do I need one?
A Playwright proxy server routes Playwright browser traffic through an intermediary IP address, masking your origin. It prevents IP bans, bypasses geo-restrictions, and makes automated sessions appear as organic user traffic.
How do I install a proxy in Playwright?
There is no separate install step. After running Playwright install, pass your proxy credentials via the proxy={"server": "...", "username": "...", "password": "..."} parameter at chromium.launch() or browser.new_context().
How do I use Playwright with proxy authentication?
Pass "username" and "password" keys inside the proxy dict at browser launch or context creation. Playwright natively handles Playwright proxy authentication without needing additional libraries.
Does Playwright support SOCKS5 proxy?
Yes. Use the socks5:// scheme in the server URL with the correst port number.
What is the difference between Playwright proxies set at browser level vs. context level?
Browser-level proxies apply to all contexts and pages. Context-level proxies allow different Playwright proxies per session, enabling multi-account workflows where each context uses a distinct IP.
Which CyberYozh proxy type is best for Playwright proxy-based Python web scraping?
Use rotating residential proxies for bulk scraping (50M+ IP pool, per-request rotation) and mobile proxies for social media targets. Datacenter proxies work for open databases requiring speed.
How do I rotate proxies in Playwright automatically?
With CyberYozh rotating residential proxies, rotation is built-in: use the -res-any suffix in your username, and every new request receives a fresh IP. No manual pool management is required.
Can I use Playwright proxy with Python's asyncio for concurrent scraping?
Yes. Use async_playwright with asyncio. Each browser.new_context(proxy=...) call can receive a different proxy config, enabling parallel sessions with distinct IPs.
Why does my Playwright scraper still get blocked even with proxies?
Blocks occur when IPs have a high fraud score, rotation is too aggressive, or browser fingerprints are inconsistent. Verify IP quality using the CyberYozh IP Checker and consider pairing proxies with an antidetect browser for high-security targets.
How do I use environment variables for Playwright proxy credentials securely?
Store credentials in a .env file (added to .gitignore), load them with python-dotenv, and pass to chromium.launch(). Never hardcode proxy strings in your source code or commit them to version control.