Configuración de proxy en Playwright
Playwright es un framework moderno de web scraping y automatización que soporta múltiples lenguajes de programación y se integra perfectamente con los proxies de CyberYozh para mayor seguridad y estabilidad de sesión. Aquí aprenderás cómo configurar Playwright y asegurarte de que tu trabajo se realice correctamente.
Preparación: Seleccionar un proxy para usar con Playwright
Antes de configurar la integración de proxy con Playwright, debes construir la infraestructura adecuada de scraping/automatización. El tipo de proxy que elijas determina el nivel de confianza, la estabilidad de sesión, la velocidad y cómo las plataformas perciben tu tráfico.
Proxy móvil: Datos sociales y geolocalización precisa
Los proxies móviles tienen la tasa de confianza más alta entre todos los tipos de proxy, lo que los convierte en la opción recomendada para el scraping de redes sociales y aplicaciones mobile-first como Instagram, TikToky Snapchat.
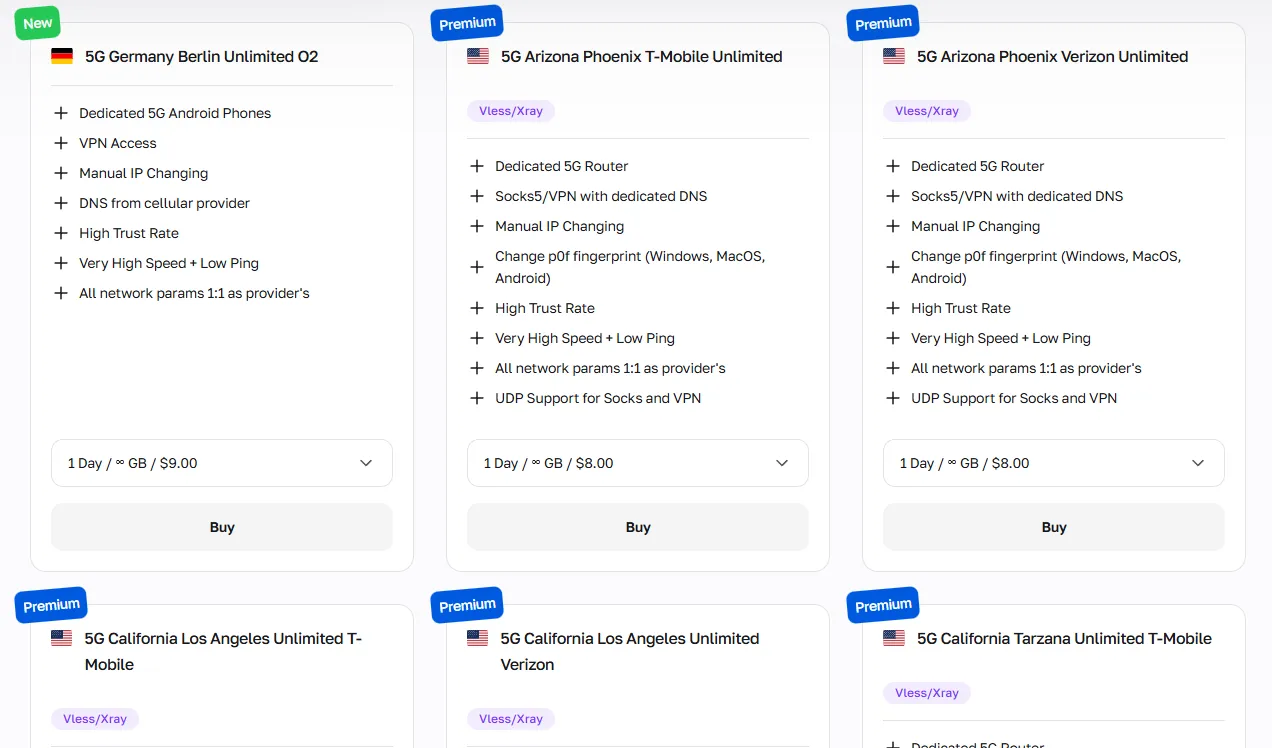
Los proxies móviles de CyberYozh ofrecen alta personalización para geolocalización precisa, configuración de huellas digitales y tráfico ilimitado; ideales cuando necesitas que Playwright emule un usuario móvil real.
Proxy residencial: Scraping general de datos y automatización
Los proxies residenciales se dividen en dos tipos según tu caso de uso:
Los proxies residenciales estáticos proporcionan una IP residencial fija de un país específico, percibida por las plataformas como un usuario ordinario de Internet doméstico. Son ideales para flujos de trabajo vinculados a cuentas.
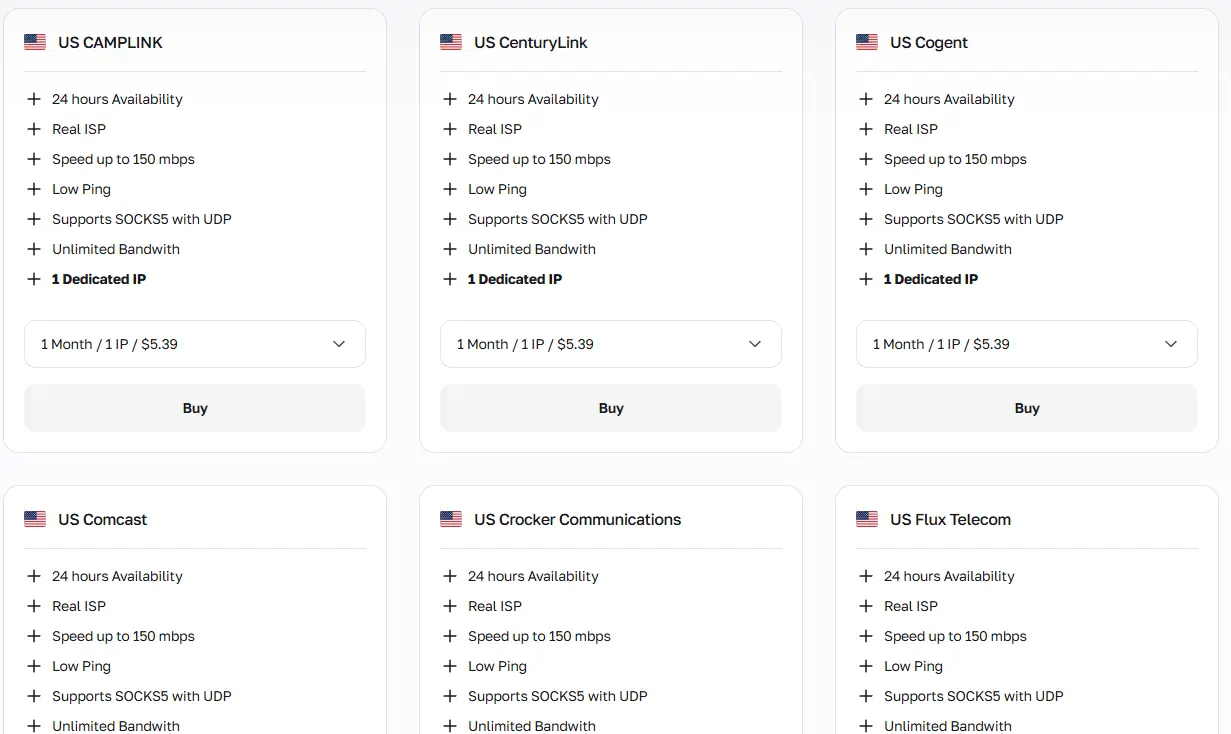
Los proxies residenciales rotativos utilizan un pool de más de 50 millones de IPs en más de 100 países, rotando direcciones por solicitud o por sesión. Son los más adecuados para automatización masiva y web scraping a gran escala con Playwright
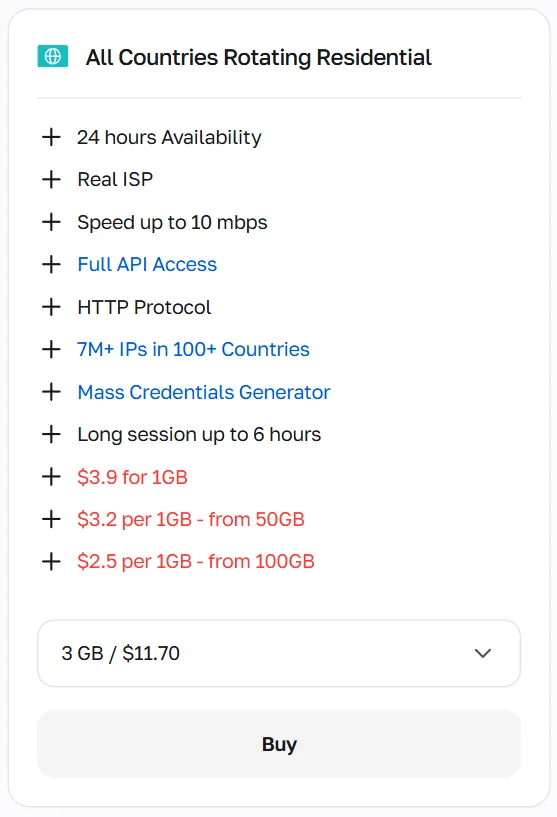
Selecciona IPs residenciales estáticas para la gestión de cuentas a largo plazo, con el esquema de 1 IP = 1 cuenta, mientras que las IPs rotativas son necesarias para todas las actividades web masivas, con una estrategia de rotación de IP adecuada basada en cada caso de uso específico.
Proxies de datacenter: Bases de datos abiertas y pruebas de aplicaciones
Los proxies de datacenter proporcionan la velocidad de conexión más rápida, pero están asociados con tráfico no residencial, similar al de bots. Funcionan bien para el scraping de bases de datos abiertas, pruebas de APIs y tareas de alta velocidad donde las plataformas aplican detección mínima de bots, pero pueden ser restringidos rápidamente en plataformas sociales como Reddit o LinkedIn.
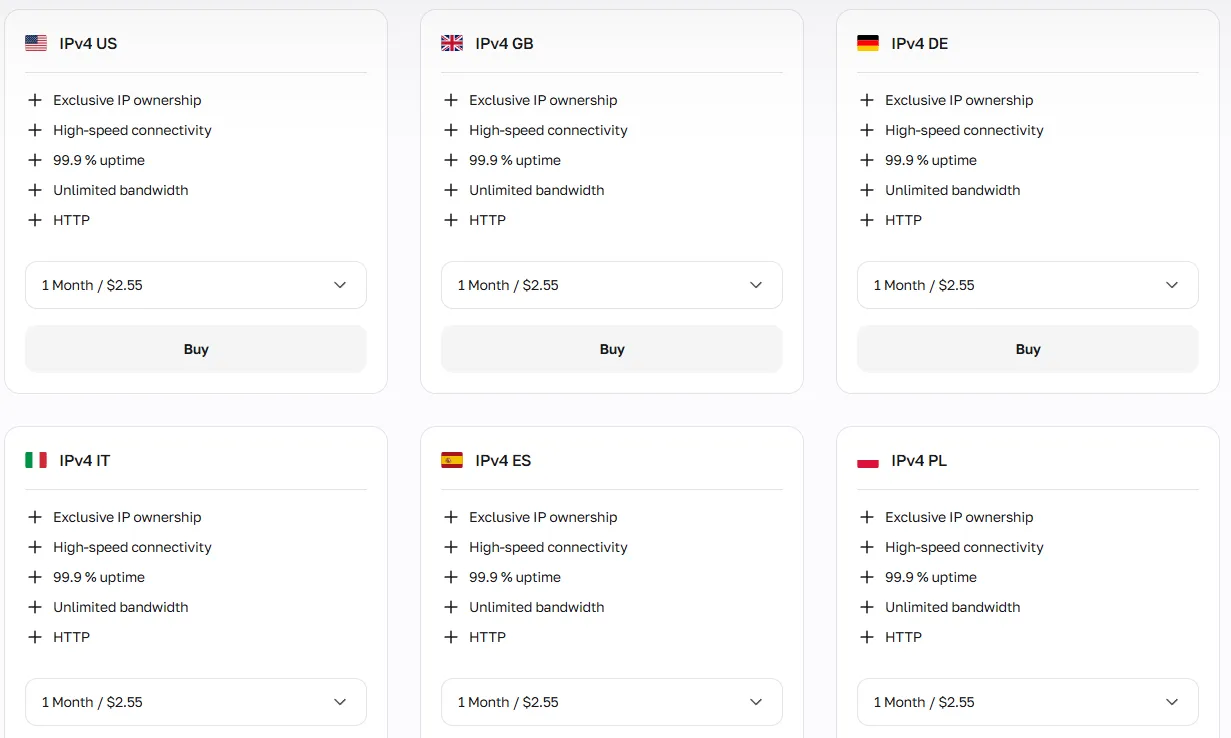
Herramienta adicional: Verificador de IP para garantizar calidad
CyberYozh ofrece un Verificador de IP que escanea cada dirección IP contra múltiples bases de datos de fraude, devolviendo una puntuación de confianza y un historial completo. Antes de rotar a una nueva IP en tu sesión de Playwright, pásala por el verificador para confirmar que no activará un baneo.
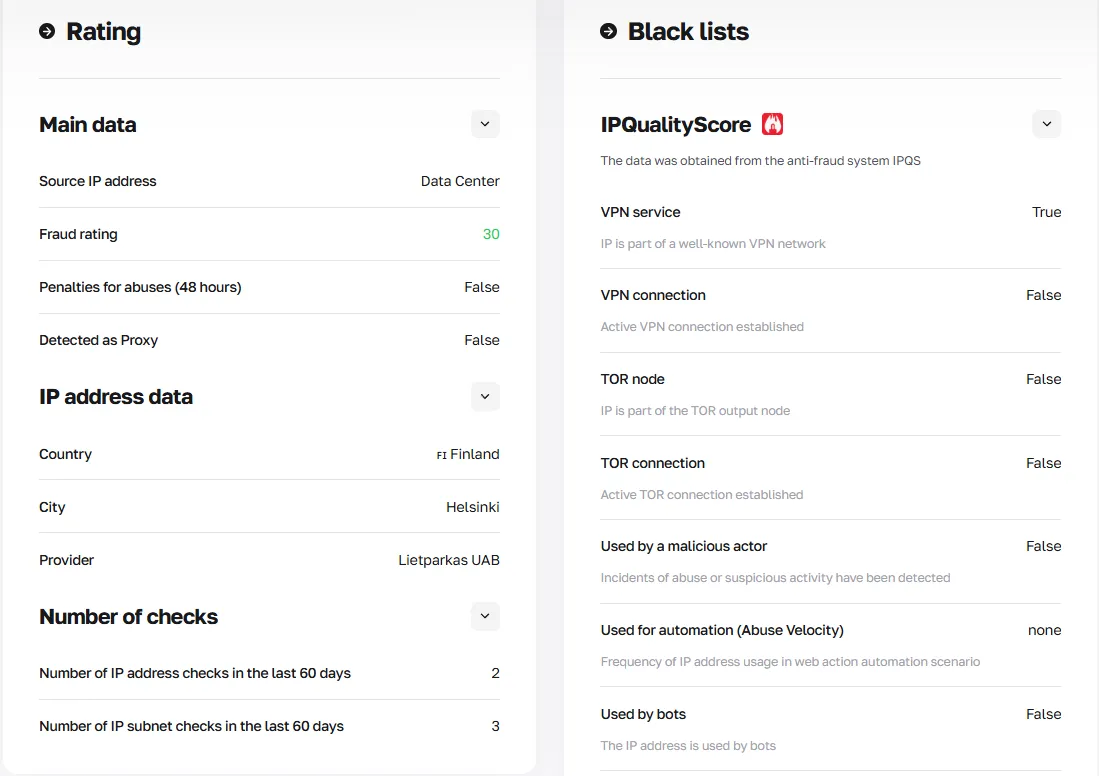
Obtén acceso a la API de CyberYozh para automatizar la rotación de IP y verificar cada dirección IP entrante antes de rotar, asegurando su calidad.
Comenzando con la instalación de Playwright: Selección de un lenguaje
Playwright soporta cuatro lenguajes. Antes de comenzar tu instalación de Playwright y configuración de proxy, elige el lenguaje que se ajuste a tu stack. Esta guía usa Python, como la opción más comúnmente utilizada para flujos de trabajo con proxy, pero las cuatro opciones están cubiertas en la tabla e instrucciones breves a continuación.
Lenguaje | Diferencias Clave | Casos de Uso Principales | Cuándo Elegir |
Node.js (JS/TS) | Lenguaje predeterminado de Playwright; soporte de TypeScript incluido; comunidad y documentación más grandes | Pruebas end-to-end, automatización de navegadores, CI/CD frontend | Tu equipo trabaja en JS/TS, o necesitas las herramientas más maduras |
Python | Más ampliamente usado en scraping/ML; async mediante asyncio; se integra con Requests, Scrapy | Web scraping, pipelines de datos, automatización de proxy, recolección de datos para ML | Necesitas scraping intensivo con proxies o integración con ciencia de datos |
.NET (C#) | Distribución NuGet; tipado fuerte, bueno para QA empresarial | Automatización de pruebas empresariales, aplicaciones .NET | Tu organización usa un stack .NET |
Java | Distribución Maven/Gradle; integración con JUnit | Aplicaciones empresariales Java, pruebas relacionadas con Android | Tu proyecto está basado en Java o requiere el ecosistema JVM |
Node.js
El lenguaje predeterminado y más completamente documentado de Playwright. TypeScript está soportado nativamente: Playwright se instala usando npm, sin necesidad de configuración adicional.
npm init playwright@latestPython
El lenguaje preferido para tareas de proxy con Playwright, scraping y automatización de datos. Requiere Python 3.8+ y usualmente se instala vía PyPI (pip).
pip install playwright
playwright install.NET (C#)
Distribuido como un paquete NuGet. Requiere PowerShell (pwsh) para ejecutar el paso de instalación del navegador.
dotnet new console -n PlaywrightDemo
cd PlaywrightDemo
dotnet add package Microsoft.Playwright
dotnet build
pwsh bin/Debug/netX/playwright.ps1 install Java
Distribuido como un módulo Maven (mvn). Agrega la dependencia a tu pom.xml en Maven, y los navegadores se descargan automáticamente en la primera compilación.
<dependency>
<groupId>com.microsoft.playwright</groupId>
<artifactId>playwright</artifactId>
<version>1.59.0</version>
</dependency> Y luego ejecuta un comando:
mvn compile exec:java -D exec.mainClass="org.example.App"Configurar un proxy de Playwright con Python
Aquí exploraremos el despliegue generalizado de una sesión de scraping con Playwright utilizando proxies de CyberYozh. Aunque el lenguaje predeterminado de Playwright es Node.js/TypeScript, usaremos Python en nuestro ejemplo, ya que Playwright con Python es ampliamente utilizado para automatización web, scraping y otras tareas relacionadas con proxies. Si necesitas usar TypeScript o tienes un caso de uso específico que requiera C# o Java, simplemente consulta la versión correspondiente de la documentación de Playwright; es bastante fácil ajustar el código.
Un servidor proxy de Playwright es un intermediario de red que retransmite las solicitudes de tu navegador a través de una dirección IP diferente. Playwright pasa la configuración del proxy directamente al momento de lanzar el navegador o a nivel de contexto, enrutando todo el tráfico a través del servidor especificado.
1. Obtén un proxy para tu tarea
Inicia sesión en tu cuenta de CyberYozh, navega a Mis Proxiesy selecciona el tipo de proxy adecuado para tu tarea (móvil, residencial estático, residencial rotativo, datacenter).
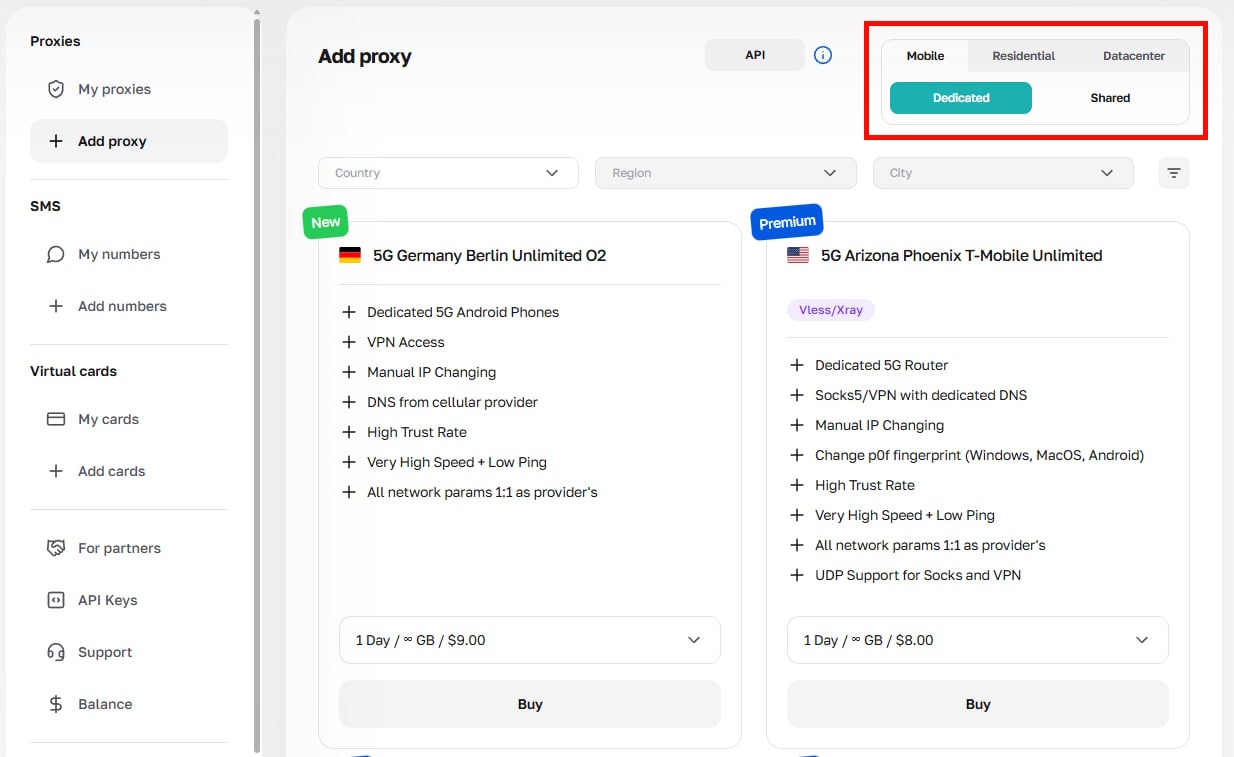
Después de la compra, abre la tarjeta del proxy, haz clic en Generar Credenciales, elige tu modo de rotación (IP aleatoria, sesión corta o sesión larga) y accede al host, puerto, nombre de usuario y contraseña.
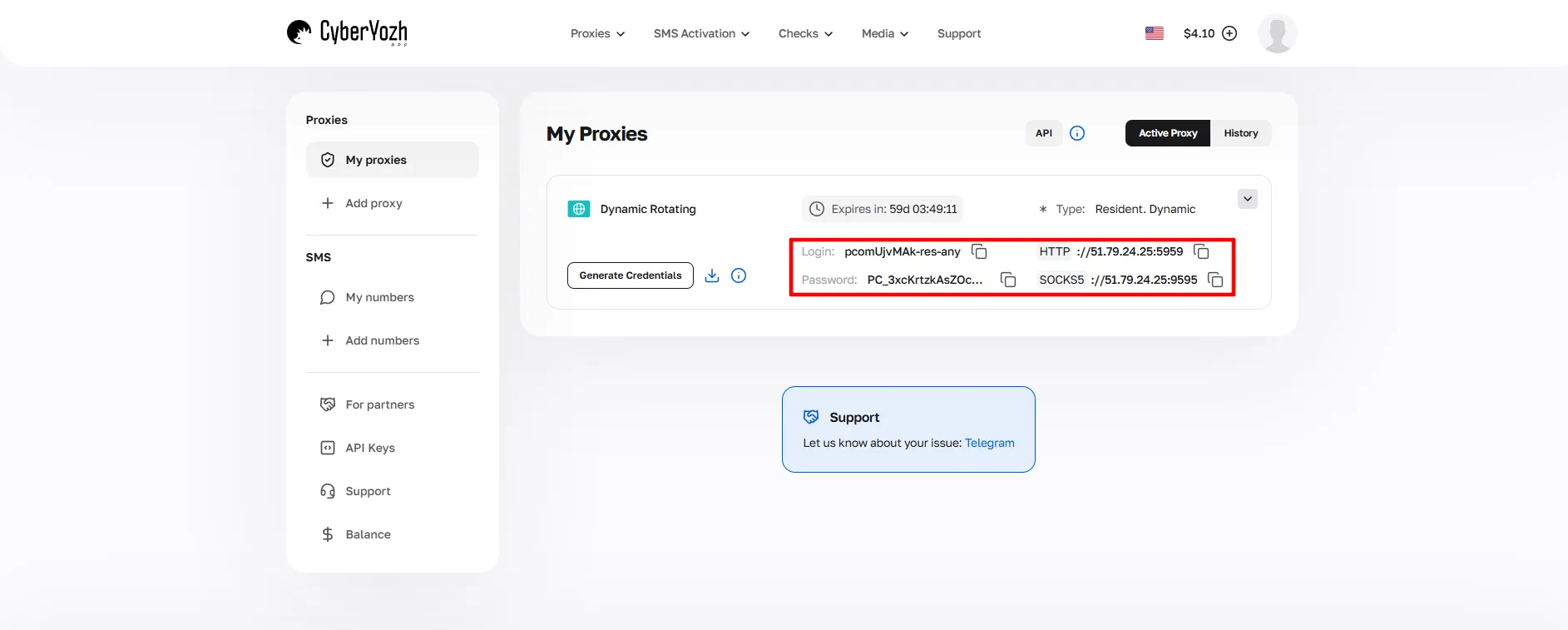
Estas credenciales se utilizarán durante toda la configuración.
2. Descarga e instala Playwright
Instala la biblioteca de Playwright y sus binarios de navegador a través de PyPI:
pip install playwright
playwright installEsto descarga los binarios de Chromium, Firefox y WebKit. Para scraping, Chromium es la opción estándar.
3. Organiza una estructura de proyecto
Crea una carpeta de proyecto dedicada (por ejemplo, scraper/). Mantén las credenciales separadas de tu código y define una ruta de salida clara para los datos extraídos:
-Documento .env para credenciales del proxy (siempre agregar a .gitignore)
-scraper.py como el script principal de Playwright
-requirements.txt para dependencias
Carpeta output/ para datos extraídos (CSV/JSON)
4. Agrega la configuración del proxy al archivo .env
Abre tu archivo .env en VS Code o cualquier editor y copia y pega tus credenciales de CyberYozh. Siempre agrega .env a tu .gitignore para evitar la filtración de credenciales a repositorios de control de versiones.
HTTP_PROXY=http://usuario:contraseña@ip-servidor-proxy:puerto
SOCKS5_PROXY=socks5://usuario:contraseña@ip-servidor-proxy:puerto
Para una configuración de proxy SOCKS5 de Playwright, usa el esquema socks5:// . Para el uso estándar de proxy HTTP de Playwright, usa el http:// . Asegúrate de incluir los puertos correctos desde el panel de CyberYozh. Si utilizas la API de CyberYozh, tu clave de API también debe especificarse aquí.
CYBERYOZH_API_KEY=Tu_Clave_URL_API
5. Crear un script de scraping/automatización
Crea el archivo de prueba en Python utilizando Playwright. Debe tener aproximadamente la siguiente estructura:
Creación de entidades de navegador y contexto con configuración de proxy
Configuración de rotación automatizada y verificación de IP mediante la API de CyberYozh
Ir al sitio web objetivo y realizar scraping mediante la biblioteca Requests
Configurar el manejo de errores
Especificar la carpeta de salida para los datos extraídos
El siguiente script implementa la configuración completa de proxy de Playwright en Python: una entidad de navegador, una entidad de contexto con autenticación de proxy de Playwright, rotación de IP automatizada mediante la API de CyberYozh, ejecución de solicitudes, manejo de errores y salida de archivos.
import asyncio
import os
import json
import requests
from dotenv import load_dotenv
from playwright.async_api import async_playwright
load_dotenv()
PROXY_URL = os.getenv("HTTP_PROXY") # or SOCKS5, from the .env document
CYBERYOZH_API_KEY = os.getenv("CYBERYOZH_API_KEY") # API key from the .env document
TARGET_URL = "https://httpbin.org/ip" # the website to scrape; here is the test one
OUTPUT_FILE = "output/results.json" # output folder
def check_ip_quality(ip: str) -> bool:
"""Use CyberYozh IP Checker API to verify trust score before rotating."""
try:
response = requests.get(
f"https://app.cyberyozh.com/api/v1/ip-check?ip={ip}",
headers={"Authorization": f"Bearer {CYBERYOZH_API_KEY}"},
timeout=5
)
score = response.json().get("fraud_score", 100)
return score < 50 # Accept IPs with fraud score below 50
except Exception:
return True # Allow on API error
async def scrape(proxy_url: str) -> dict:
"""Run a single Playwright scraping session with proxy."""
# Parse proxy credentials for Playwright proxy authentication
from urllib.parse import urlparse
parsed = urlparse(proxy_url)
proxy_config = {
"server": f"{parsed.scheme}://{parsed.hostname}:{parsed.port}",
"username": parsed.username,
"password": parsed.password,
}
async with async_playwright() as p:
# Browser entity (headless to save traffic): launch with proxy server
browser = await p.chromium.launch(headless=True)
# Context entity: proxy settings applied per context
context = await browser.new_context(proxy=proxy_config)
page = await context.new_page()
try:
await page.goto(TARGET_URL, timeout=30000)
content = await page.inner_text("body")
result = json.loads(content)
return {"status": "ok", "ip": result.get("origin")}
except Exception as e:
return {"status": "error", "error": str(e)}
finally:
await context.close()
await browser.close()
async def main():
results = []
for i in range(5):
print(f"Request {i+1}: using proxy {PROXY_URL}")
data = await scrape(PROXY_URL)
print(f" → IP: {data.get('ip')} | Status: {data.get('status')}")
results.append(data)
os.makedirs("output", exist_ok=True)
with open(OUTPUT_FILE, "w") as f:
json.dump(results, f, indent=2)
print(f"Results saved to {OUTPUT_FILE}")
asyncio.run(main())Consulta también la guía relacionada: Configuración de Rotación de Proxy en Python.
6. Ejecutar la prueba y rotar el proxy
Inicia el scraper desde la raíz de tu proyecto:
python scraper.pyVerifica que cada solicitud registre una dirección IP diferente (confirmando que la rotación está activa) y que el archivo output/results.json esté poblado. Utiliza la API de CyberYozh para rotación automatizada y verificaciones de calidad automatizadas mediante el IP Checker: los proxies con una puntuación de fraude alta serán rechazados antes del siguiente ciclo de rotación.
Ver también: Guía de Automatización de Web Scraping
Resumen: Uso de Playwright con la infraestructura de CyberYozh
Con los proxies de Playwright configurados y las credenciales de CyberYozh activas, puedes ejecutar scraping multi-objetivo, automatización geo-dirigida y flujos de trabajo de gestión de cuentas a escala, enrutando cada sesión de navegador a través de IPs residenciales o móviles limpias con validación de puntuación de fraude, mientras generas datos estructurados en el formato que elijas.
Preguntas frecuentes
¿Qué es un servidor proxy de Playwright y por qué necesito uno?
Un servidor proxy de Playwright enruta el tráfico del navegador de Playwright a través de una dirección IP intermediaria, ocultando tu origen. Previene bloqueos de IP, evita restricciones geográficas y hace que las sesiones automatizadas parezcan tráfico de usuario orgánico.
¿Cómo instalo un proxy en Playwright?
No hay un paso de instalación separado. Después de ejecutar Playwright install, pasa tus credenciales de proxy mediante el parámetro proxy={"server": "...", "username": "...", "password": "..."} en chromium.launch() o browser.new_context().
¿Cómo uso Playwright con autenticación de proxy?
Pasa las claves "username" y "password" dentro del diccionario proxy al iniciar el navegador o crear el contexto. Playwright maneja nativamente la autenticación de proxy de Playwright sin necesidad de bibliotecas adicionales.
¿Playwright admite proxy SOCKS5?
Sí. Utiliza el esquema socks5:// en la URL del servidor con el número de puerto correcto.
¿Cuál es la diferencia entre los proxies de Playwright configurados a nivel de navegador vs. a nivel de contexto?
Los proxies a nivel de navegador se aplican a todos los contextos y páginas. Los proxies a nivel de contexto permiten diferentes proxies de Playwright por sesión, habilitando flujos de trabajo multi-cuenta donde cada contexto usa una IP distinta.
¿Qué tipo de proxy de CyberYozh es mejor para web scraping con Python basado en proxies de Playwright?
Usa proxies residenciales rotativos para scraping masivo (pool de más de 50M de IPs, rotación por solicitud) y proxies móviles para objetivos de redes sociales. Los proxies de datacenter funcionan para bases de datos abiertas que requieren velocidad.
¿Cómo roto proxies en Playwright automáticamente?
Con los proxies residenciales rotativos de CyberYozh, la rotación está integrada: usa el sufijo -res-any en tu nombre de usuario, y cada nueva solicitud recibe una IP nueva. No se requiere gestión manual del pool.
¿Puedo usar proxies de Playwright con asyncio de Python para scraping concurrente?
Sí. Usa async_playwright con asyncio. Cada llamada a browser.new_context(proxy=...) puede recibir una configuración de proxy diferente, habilitando sesiones paralelas con IPs distintas.
¿Por qué mi scraper de Playwright sigue siendo bloqueado incluso con proxies?
Los bloqueos ocurren cuando las IPs tienen una puntuación de fraude alta, la rotación es demasiado agresiva, o las huellas digitales del navegador son inconsistentes. Verifica la calidad de las IPs usando el CyberYozh IP Checker y considera combinar proxies con un navegador antidetección para objetivos de alta seguridad.
¿Cómo uso variables de entorno para las credenciales de proxies de Playwright de forma segura?
Almacena las credenciales en un archivo .env (agregado a .gitignore), cárgalas con python-dotenv, y pásalas a chromium.launch(). Nunca codifiques cadenas de proxy directamente en tu código fuente ni las confirmes en el control de versiones.