Configuração de proxy no Playwright
Playwright é um framework moderno de web scraping e automação que suporta múltiplas linguagens de programação e integra-se bem com proxies CyberYozh para segurança adicional e estabilidade de sessão. Aqui, aprenda como configurar o Playwright e garantir que seu trabalho seja bem executado.
Preparação: Selecionando um proxy para usar com Playwright
Antes de configurar uma integração de proxy com Playwright, você deve construir a infraestrutura adequada de scraping/automação. O tipo de proxy determina o nível de confiança, estabilidade de sessão, velocidade e como as plataformas percebem seu tráfego.
Proxy móvel: Dados sociais e geotargeting preciso
Proxies móveis possuem a maior taxa de confiança entre todos os tipos de proxy, tornando-os a escolha recomendada para scraping de redes sociais e aplicações mobile-first como Instagram, TikTok, e Snapchat.
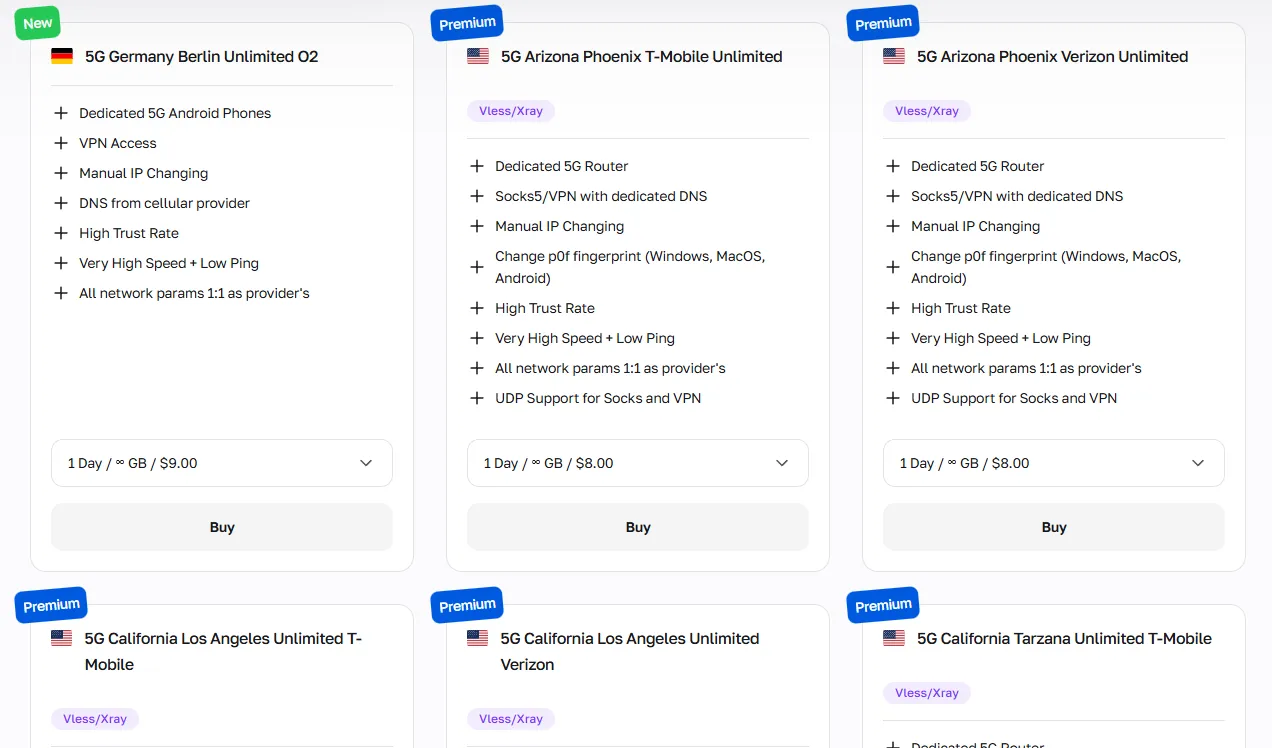
Os proxies móveis da CyberYozh oferecem alta personalização para geotargeting preciso, configurações de fingerprint e tráfego ilimitado; ideal quando você precisa que o Playwright emule um usuário móvel real.
Proxy residencial: Scraping geral de dados e automação
Os proxies residenciais são divididos em dois tipos com base no seu caso de uso:
Proxies residenciais estáticos fornecem um IP residencial fixo de um país específico, percebido pelas plataformas como um usuário comum de Internet doméstica. São ideais para fluxos de trabalho vinculados a contas.
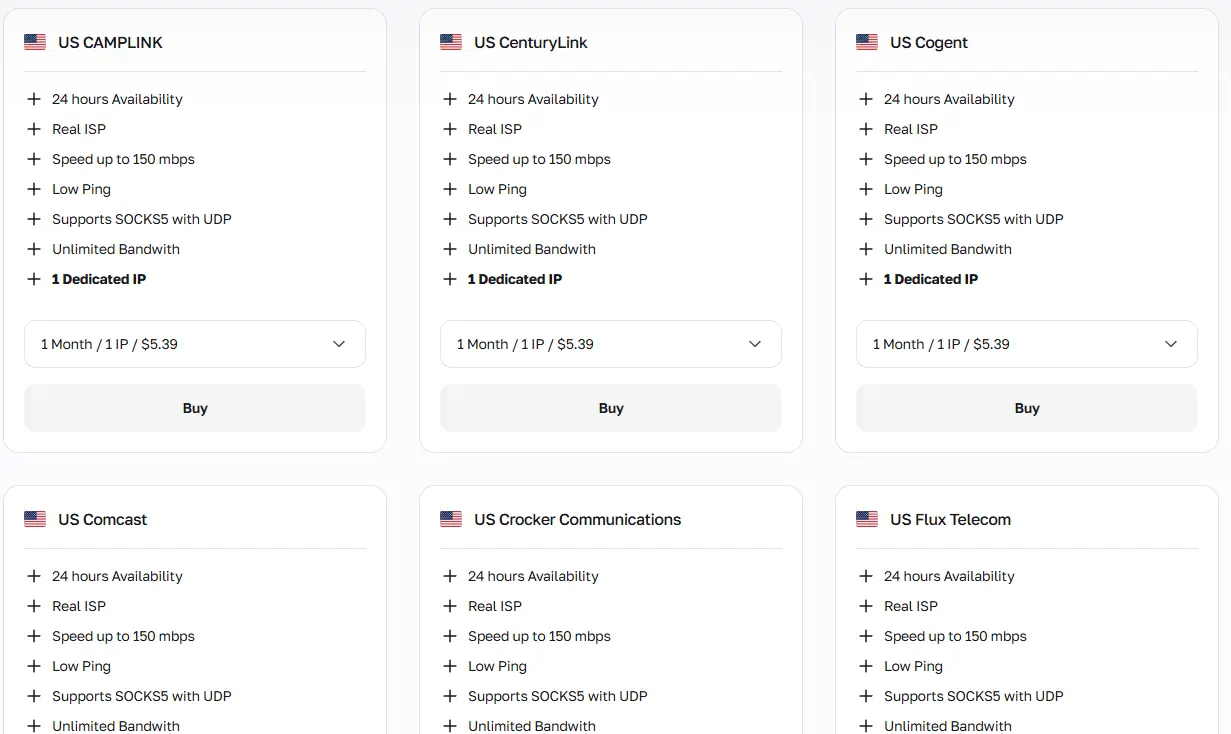
Proxies residenciais rotativos usam um pool de mais de 50 milhões de IPs em mais de 100 países, rotacionando endereços por requisição ou por sessão. São mais adequados para automação em massa e web scraping em larga escala com Playwright
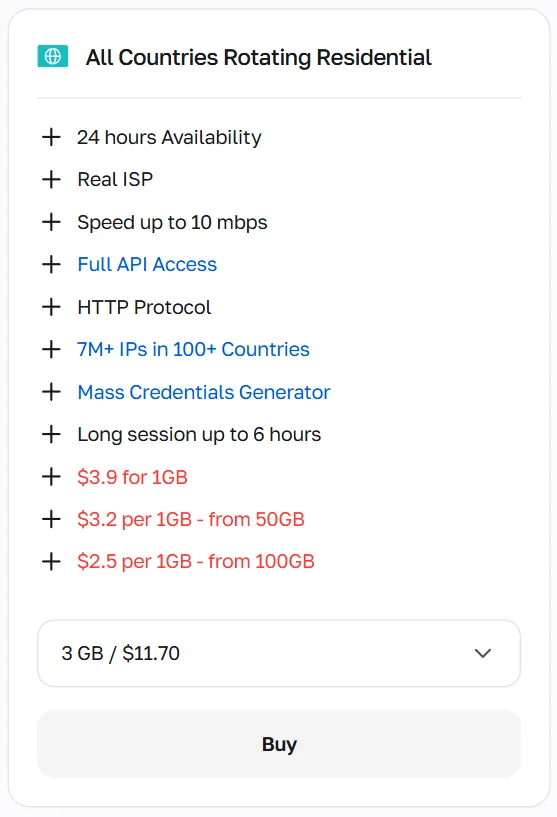
Selecione IPs residenciais estáticos para gestão de contas a longo prazo, com o esquema de 1 IP = 1 conta, enquanto IPs rotativos são necessários para todas as atividades web em massa, com uma estratégia de rotação de IP adequada baseada em cada caso de uso específico.
Proxies de datacenter: Bancos de dados abertos e testes de aplicações
Proxies de datacenter fornecem a velocidade de conexão mais rápida, mas estão associados a tráfego não residencial, semelhante a bots. Funcionam bem para scraping de bancos de dados abertos, testes de APIs e tarefas de alta velocidade onde as plataformas aplicam detecção mínima de bots, mas podem ser rapidamente restritos em plataformas sociais como Reddit ou LinkedIn.
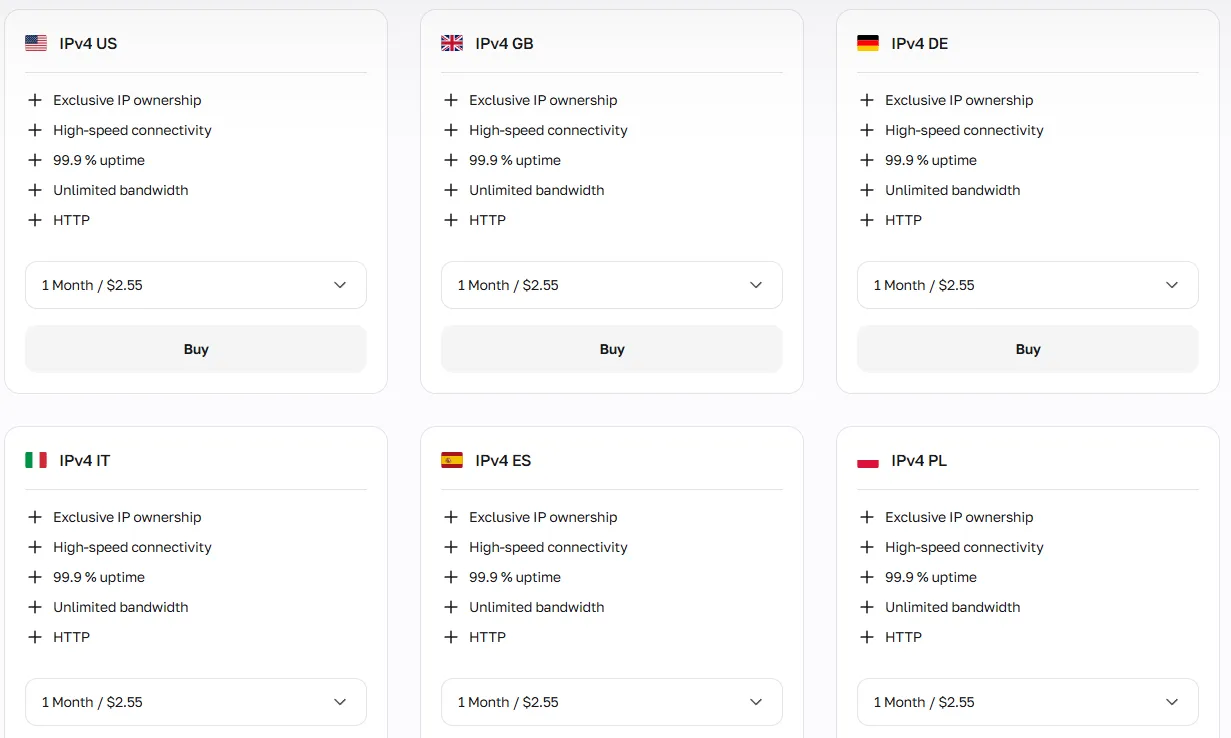
Ferramenta adicional: Verificador de IP para garantir qualidade
A CyberYozh oferece um Verificador de IP que escaneia cada endereço IP em múltiplos bancos de dados de fraude, retornando uma pontuação de confiança e histórico completo. Antes de rotacionar para um novo IP na sua sessão Playwright, execute-o através do verificador para confirmar que não acionará um banimento.
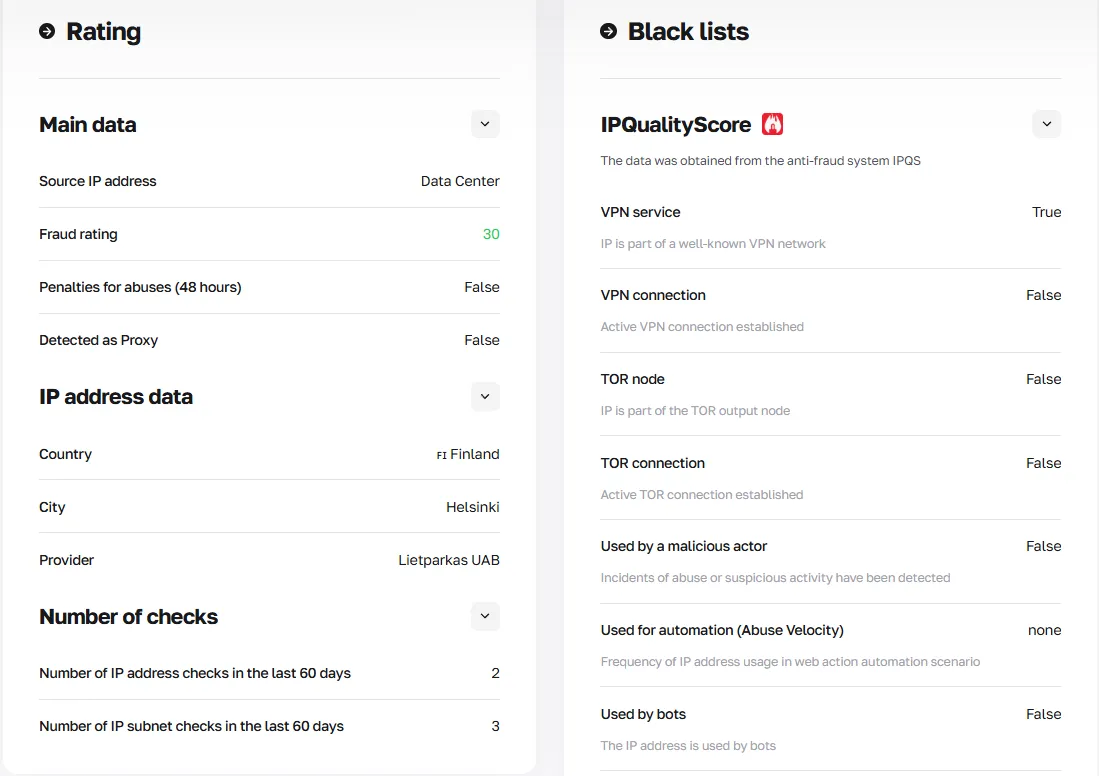
Obtenha acesso à API da CyberYozh para automatizar a rotação de IP e verificar cada endereço IP recebido antes de rotacionar, garantindo sua qualidade.
Começando com a instalação do Playwright: Selecionando uma linguagem
O Playwright suporta quatro linguagens. Antes de iniciar a instalação do Playwright e a configuração de proxy, escolha a linguagem que se adequa à sua stack. Este guia usa Python, como a escolha mais comum para fluxos de trabalho com proxy, mas todas as quatro opções estão cobertas na tabela e nas instruções resumidas abaixo.
Linguagem | Principais Diferenças | Casos de Uso Primários | Quando Escolher |
Node.js (JS/TS) | Linguagem padrão do Playwright; suporte a TypeScript pronto para uso; maior comunidade e documentação | Testes end-to-end, automação de navegadores, CI/CD frontend | Sua equipe trabalha com JS/TS, ou você precisa das ferramentas mais maduras |
Python | Mais amplamente usado em scraping/ML; async via asyncio; integra com Requests, Scrapy | Web scraping, pipelines de dados, automação de proxy, coleta de dados para ML | Você precisa de scraping intensivo com proxy ou integração com ciência de dados |
.NET (C#) | Distribuição via NuGet; tipagem forte, bom para QA empresarial | Automação de testes empresariais, aplicações .NET | Sua organização usa uma stack .NET |
Java | Distribuição via Maven/Gradle; integração com JUnit | Aplicações empresariais Java, testes relacionados a Android | Seu projeto é baseado em Java ou requer o ecossistema JVM |
Node.js
A linguagem padrão e mais completamente documentada do Playwright. TypeScript é suportado nativamente: o Playwright é instalado usando npm, sem necessidade de configuração extra.
npm init playwright@latestPython
A linguagem preferida para tarefas de proxy do Playwright, scraping e automação de dados. Requer Python 3.8+ e geralmente é instalado via PyPI (pip).
pip install playwright
playwright install.NET (C#)
Distribuído como um pacote NuGet. Requer PowerShell (pwsh) para executar a etapa de instalação do navegador.
dotnet new console -n PlaywrightDemo
cd PlaywrightDemo
dotnet add package Microsoft.Playwright
dotnet build
pwsh bin/Debug/netX/playwright.ps1 install Java
Distribuído como um módulo Maven (mvn). Adicione a dependência ao seu pom.xml no Maven, e os navegadores são baixados automaticamente na primeira compilação.
<dependency>
<groupId>com.microsoft.playwright</groupId>
<artifactId>playwright</artifactId>
<version>1.59.0</version>
</dependency> E então execute um comando:
mvn compile exec:java -D exec.mainClass="org.example.App"Configurando um proxy Playwright com Python
Aqui, vamos explorar a implementação generalizada de uma sessão de scraping com Playwright usando proxies CyberYozh. Embora a linguagem padrão do Playwright seja Node.js/TypeScript, usaremos Python em nosso exemplo, pois o Playwright com Python é amplamente utilizado para automação web, scraping e outras tarefas relacionadas a proxy. Se você precisar usar TypeScript ou tiver um caso de uso específico que exija C# ou Java, basta explorar a versão correspondente da documentação do Playwright; é bastante fácil ajustar o código.
Um servidor proxy Playwright é um intermediário de rede que retransmite as solicitações do seu navegador através de um endereço IP diferente. O Playwright passa a configuração do proxy diretamente no lançamento do navegador ou no nível de contexto, roteando todo o tráfego através do servidor especificado.
1. Obtenha um proxy para sua tarefa
Faça login na sua conta CyberYozh, navegue até Meus Proxiese selecione o tipo de proxy adequado para sua tarefa (móvel, residencial estático, residencial rotativo, datacenter).
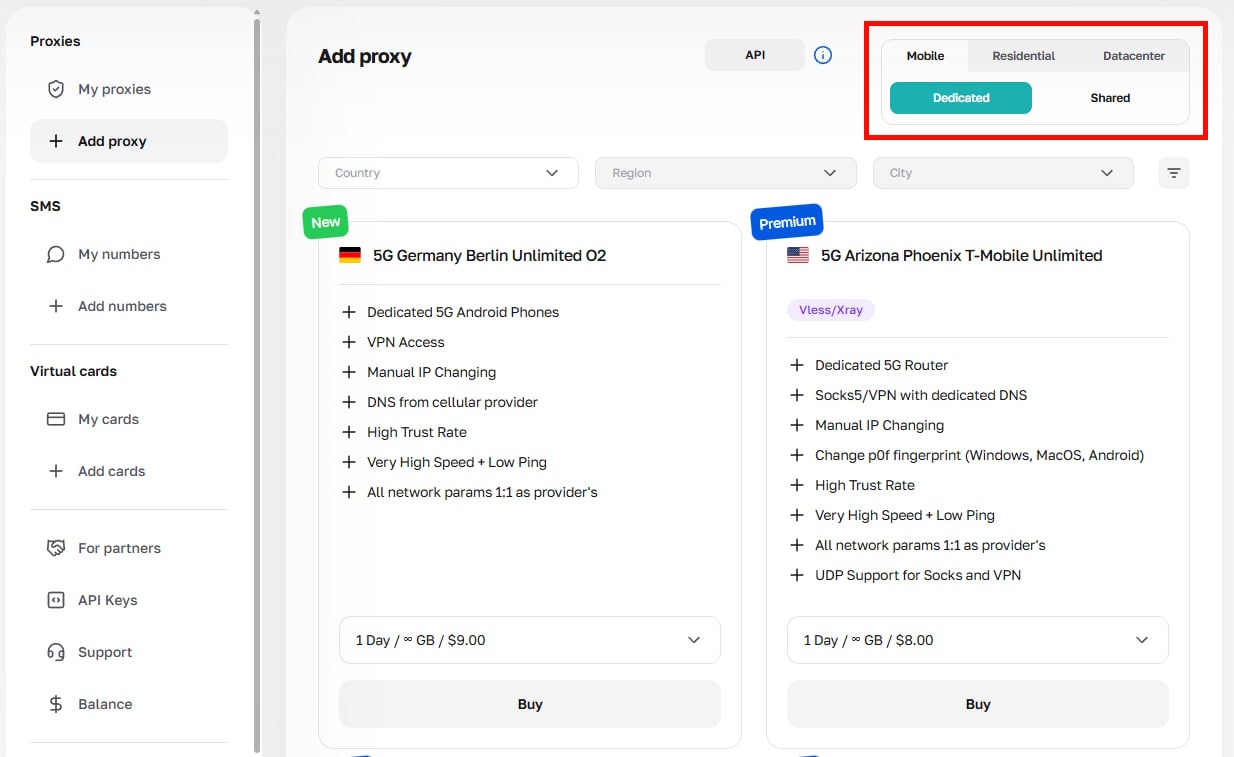
Após a compra, abra o cartão do proxy, clique em Gerar Credenciais, escolha seu modo de rotação (IP Aleatório, Sessão Curta ou Sessão Longa) e navegue até o host, porta, nome de usuário e senha.
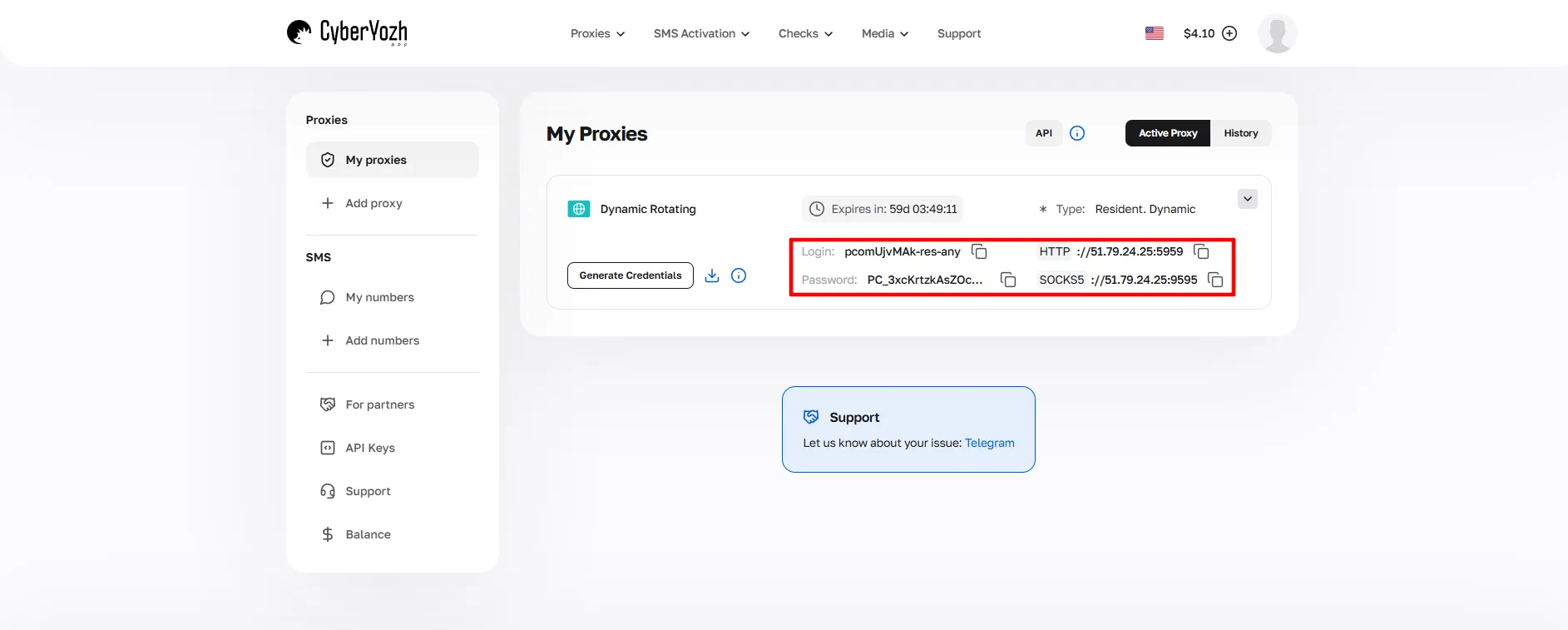
Essas credenciais serão usadas durante toda a configuração.
2. Baixe e instale o Playwright
Instale a biblioteca Playwright e seus binários de navegador via PyPI:
pip install playwright
playwright installIsso baixa os binários do Chromium, Firefox e WebKit. Para scraping, o Chromium é a escolha padrão.
3. Organize uma estrutura de projeto
Crie uma pasta de projeto dedicada (por exemplo, scraper/). Mantenha as credenciais separadas do seu código e defina um caminho de saída claro para os dados extraídos:
- documento .env para credenciais de proxy (sempre adicione ao .gitignore)
- scraper.py como o script principal do Playwright
- requirements.txt para dependências
pasta output/ para dados extraídos (CSV/JSON)
4. Adicione a configuração de proxy no arquivo .env
Abra seu arquivo .env no VS Code ou qualquer editor e copie e cole suas credenciais CyberYozh. Sempre adicione .env ao seu .gitignore para evitar vazamento de credenciais para repositórios de controle de versão.
HTTP_PROXY=http://username:password@proxy-server-ip:host
SOCKS5_PROXY=socks5://username:password@proxy-server-ip:host
Para uma configuração de proxy SOCKS5 do Playwright, use o esquema socks5:// . Para uso padrão de proxy HTTP do Playwright, use o http:// . Certifique-se de incluir as portas corretas do painel do CyberYozh. Se você usar a API do CyberYozh, sua chave de API também deve ser especificada aqui.
CYBERYOZH_API_KEY=Sua_Chave_URL_API
5. Criar um script de scraping/automação
Crie o arquivo de teste Python usando o Playwright. Ele deve ter aproximadamente a seguinte estrutura:
Criação de entidades de navegador e contexto com configurações de proxy
Configuração de rotação automatizada e verificação de IP via API do CyberYozh
Acessar o site de destino e realizar scraping através da biblioteca Requests
Configurar tratamento de erros
Especificar a pasta de saída para os dados extraídos
O script abaixo implementa a configuração completa de proxy do Playwright em Python: uma entidade de navegador, uma entidade de contexto com autenticação de proxy do Playwright, rotação automática de IP via API do CyberYozh, execução de requisições, tratamento de erros e saída de arquivo.
import asyncio
import os
import json
import requests
from dotenv import load_dotenv
from playwright.async_api import async_playwright
load_dotenv()
PROXY_URL = os.getenv("HTTP_PROXY") # or SOCKS5, from the .env document
CYBERYOZH_API_KEY = os.getenv("CYBERYOZH_API_KEY") # API key from the .env document
TARGET_URL = "https://httpbin.org/ip" # the website to scrape; here is the test one
OUTPUT_FILE = "output/results.json" # output folder
def check_ip_quality(ip: str) -> bool:
"""Use CyberYozh IP Checker API to verify trust score before rotating."""
try:
response = requests.get(
f"https://app.cyberyozh.com/api/v1/ip-check?ip={ip}",
headers={"Authorization": f"Bearer {CYBERYOZH_API_KEY}"},
timeout=5
)
score = response.json().get("fraud_score", 100)
return score < 50 # Accept IPs with fraud score below 50
except Exception:
return True # Allow on API error
async def scrape(proxy_url: str) -> dict:
"""Run a single Playwright scraping session with proxy."""
# Parse proxy credentials for Playwright proxy authentication
from urllib.parse import urlparse
parsed = urlparse(proxy_url)
proxy_config = {
"server": f"{parsed.scheme}://{parsed.hostname}:{parsed.port}",
"username": parsed.username,
"password": parsed.password,
}
async with async_playwright() as p:
# Browser entity (headless to save traffic): launch with proxy server
browser = await p.chromium.launch(headless=True)
# Context entity: proxy settings applied per context
context = await browser.new_context(proxy=proxy_config)
page = await context.new_page()
try:
await page.goto(TARGET_URL, timeout=30000)
content = await page.inner_text("body")
result = json.loads(content)
return {"status": "ok", "ip": result.get("origin")}
except Exception as e:
return {"status": "error", "error": str(e)}
finally:
await context.close()
await browser.close()
async def main():
results = []
for i in range(5):
print(f"Request {i+1}: using proxy {PROXY_URL}")
data = await scrape(PROXY_URL)
print(f" → IP: {data.get('ip')} | Status: {data.get('status')}")
results.append(data)
os.makedirs("output", exist_ok=True)
with open(OUTPUT_FILE, "w") as f:
json.dump(results, f, indent=2)
print(f"Results saved to {OUTPUT_FILE}")
asyncio.run(main())Veja também o guia relacionado: Configurando Rotação de Proxy em Python.
6. Executar o teste e rotacionar o proxy
Inicie o scraper a partir da raiz do seu projeto:
python scraper.pyVerifique se cada requisição registra um endereço IP diferente (confirmando que a rotação está ativa) e se o arquivo output/results.json está sendo preenchido. Use a API do CyberYozh para rotação automatizada e verificações de qualidade automatizadas via IP Checker: proxies com alta pontuação de fraude serão rejeitados antes do próximo ciclo de rotação.
Veja também: Guia de Automação de Web Scraping
Resumo: Usando Playwright com a infraestrutura do CyberYozh
Com os proxies do Playwright configurados e as credenciais do CyberYozh ativas, você pode executar scraping multi-alvo, automação geo-direcionada e fluxos de trabalho de gerenciamento de contas em escala, roteando cada sessão do navegador através de IPs residenciais ou móveis limpos com validação de pontuação de fraude, enquanto gera dados estruturados no formato escolhido.
Perguntas Frequentes
O que é um servidor proxy do Playwright e por que preciso de um?
Um servidor proxy do Playwright roteia o tráfego do navegador Playwright através de um endereço IP intermediário, mascarando sua origem. Ele previne banimentos de IP, contorna restrições geográficas e faz com que sessões automatizadas pareçam tráfego orgânico de usuários.
Como instalo um proxy no Playwright?
Não há uma etapa de instalação separada. Após executar Playwright install, passe suas credenciais de proxy através do parâmetro proxy={"server": "...", "username": "...", "password": "..."} em chromium.launch() ou browser.new_context().
Como uso o Playwright com autenticação de proxy?
Passe as chaves "username" e "password" dentro do dicionário proxy na inicialização do navegador ou criação do contexto. O Playwright lida nativamente com autenticação de proxy do Playwright sem precisar de bibliotecas adicionais.
O Playwright suporta proxy SOCKS5?
Sim. Use o socks5:// no URL do servidor com o número de porta correto.
Qual é a diferença entre proxies do Playwright definidos ao nível do navegador vs. ao nível do contexto?
Proxies ao nível do navegador aplicam-se a todos os contextos e páginas. Proxies ao nível do contexto permitem diferentes proxies do Playwright por sessão, possibilitando fluxos de trabalho multi-conta onde cada contexto usa um IP distinto.
Qual tipo de proxy do CyberYozh é melhor para web scraping em Python baseado em proxy do Playwright?
Use proxies residenciais rotativos para scraping em massa (pool de 50M+ IPs, rotação por requisição) e proxies móveis para alvos de redes sociais. Proxies de datacenter funcionam para bases de dados abertas que exigem velocidade.
Como faço para rodar proxies no Playwright automaticamente?
Com os proxies residenciais rotativos do CyberYozh, a rotação é incorporada: use o sufixo -res-any no seu nome de usuário, e cada nova requisição recebe um IP novo. Não é necessária gestão manual do pool.
Posso usar proxy do Playwright com asyncio do Python para scraping concorrente?
Sim. Use async_playwright com asyncio. Cada chamada browser.new_context(proxy=...) pode receber uma configuração de proxy diferente, possibilitando sessões paralelas com IPs distintos.
Por que meu scraper do Playwright ainda é bloqueado mesmo com proxies?
Bloqueios ocorrem quando os IPs têm uma pontuação de fraude elevada, a rotação é demasiado agressiva, ou as impressões digitais do navegador são inconsistentes. Verifique a qualidade do IP usando o IP Checker do CyberYozh e considere combinar proxies com um navegador antidetecção para alvos de alta segurança.
Como uso variáveis de ambiente para credenciais de proxy do Playwright de forma segura?
Armazene as credenciais num ficheiro .env (adicionado ao .gitignore), carregue-as com python-dotenv, e passe para chromium.launch(). Nunca codifique strings de proxy diretamente no seu código-fonte ou as envie para controlo de versão.