
En el mundo del e-commerce, los datos son el nuevo petróleo. Quien posee la información sobre precios, surtido y estrategias de la competencia, domina el mercado. Los marketplaces como Amazon, Ozon, Wildberries o Alibaba son bases de datos gigantescas y constantemente actualizadas que contienen esta valiosa información. Obtenerla significa conseguir una ventaja competitiva decisiva.
La única forma de extraer estos datos a escala industrial es mediante el parsing (o web scraping). Pero hay un problema: los marketplaces lo saben perfectamente y se defienden activamente.
En este artículo, analizaremos cómo construir un sistema de recopilación de datos eficaz y escalable para analítica e inteligencia competitiva utilizando las configuraciones de proxy adecuadas.
Nota importante: Al automatizar la recopilación de datos, asegúrese de que sus acciones cumplan con la legislación (incluidos GDPR y DMCA) y no infrinjan los Términos de Servicio (ToS) de las plataformas de destino. Utilice los proxies de forma responsable: evite crear una carga crítica en los servidores y respete la ética del web scraping.
¿Por qué los marketplaces no quieren que se haga scraping de ellos?
La recopilación manual de datos es ineficiente y lenta. El scraping automatizado permite obtener enormes conjuntos de datos en poco tiempo. Es por eso que los marketplaces construyen escalones enteros de defensa:
- Bloqueo por IP. El método de protección más básico y eficaz. Si desde una dirección IP llega una cantidad de peticiones anómalamente alta, esta entra inmediatamente en baneo temporal o permanente.
- Rate Limiting (limitación de frecuencia de peticiones). El sistema permite realizar, por ejemplo, no más de 30 peticiones por minuto desde una IP. Todo lo que supere el límite se bloquea.
- CAPTCHA. Si el sistema detecta signos de automatización, presenta al usuario un captcha que un scraper estándar no puede superar.
- Geobloqueos. Los precios, el surtido y las condiciones de envío en un mismo marketplace pueden variar drásticamente para usuarios de EE. UU. y Alemania. Sin una dirección IP de la región adecuada, simplemente no verá datos relevantes.
Análisis de Fingerprint (huella digital). Los sistemas avanzados analizan cientos de parámetros de su navegador. Ejemplos de lo que comprueban exactamente los marketplaces:
Canvas y WebGL fingerprinting: los sitios obligan al navegador a dibujar una figura oculta de forma invisible. La manera exacta en que su tarjeta de vídeo y sus controladores renderizan los píxeles crea un identificador único del dispositivo.
Huellas de audio: comprobación de cómo procesa su sistema las señales de audio.
Encabezados técnicos: una discrepancia entre la versión del User-Agent y las fuentes instaladas o la resolución de pantalla lo marca instantáneamente como un bot.
Proxy: su llave a los datos. Pero no cualquiera.
Un servidor proxy es el cimiento tecnológico de cualquier scraper profesional. Actúa como un intermediario inteligente: enruta sus peticiones a través de diferentes direcciones IP para garantizar una recopilación de datos de alta carga y mantener la privacidad.
Sin embargo, hay que entender que, en las realidades modernas, incluso los proxies de mayor calidad requieren una integración correcta. Para obtener datos de forma estable bajo cargas intensas, los proxies deben estar correctamente integrados en su arquitectura. Si su IP es una dirección residencial "limpia", pero los parámetros de la petición están mal configurados, el sistema puede rechazar la conexión.
Para lograr el máximo resultado, los proxies deben combinarse con una configuración adecuada de encabezados (headers) y una gestión de la frecuencia de peticiones para asegurar una conexión estable.
¿Por qué el tipo de proxy tiene una importancia crucial?
No todos los tipos de conexiones son adecuados para el scraping de marketplaces. A continuación, analizaremos los tipos principales y determinaremos para qué tareas será más eficaz cada uno.
Tipos de proxies y su aplicabilidad:
Proxies residenciales rotativos — la opción nº 1 para el scraping masivo
Son direcciones IP dinámicas de usuarios domésticos reales.
Ventajas: Enormes pools (millones de IPs) en todo el mundo. Una petición desde esta dirección parece para el marketplace la visita de un comprador común a través de su Wi-Fi doméstico.
Veredicto: Ideales para recopilar grandes volúmenes de datos: monitorización de precios, existencias y contenido de fichas de producto.
Configuración flexible de sesiones: Dependiendo de sus tareas, puede elegir uno de los tres modos de funcionamiento:
IP aleatoria: Cambio automático de dirección en cada nueva petición.
Sesión corta: Mantenimiento de una IP por un periodo de hasta 1 minuto (útil para cadenas rápidas de acciones).
Sesión larga (Sticky): Fijación de la IP por un tiempo prolongado — estrictamente hasta 6 horas (necesario para simular una estancia larga del usuario en el sitio).
Proxies residenciales estáticos (ISP) — para trabajar a largo plazo
Son IPs limpias de proveedores domésticos que se le asignan durante todo el periodo de alquiler.
Ventajas: Combinan la confianza de una dirección residencial y la estabilidad de un canal de servidor. La IP no cambia, lo cual es crítico para los sistemas de protección.
Veredicto: Indispensables para gestionar cuentas de vendedores, administrar paneles publicitarios y trabajar con cuentas personales donde una dirección IP constante es crítica para mantener un acceso seguro y continuo a los recursos corporativos.
Proxies móviles privados — la solución definitiva
Utilizan direcciones IP de operadores de telefonía móvil (4G/5G).
Ventajas: El nivel más alto de confianza. Gracias a la tecnología CGNAT, una misma IP es compartida por miles de personas reales, por lo que los marketplaces prácticamente nunca bloquean estas direcciones.
Puertos dedicados: Para garantizar un alto porcentaje de conexiones exitosas y una comunicación fiable en entornos complejos de alta carga y arquitecturas de scraping exigentes, recomendamos los puertos móviles dedicados. Ofrecen un canal individual, máxima velocidad y estabilidad sin "vecinos".
Proxies de centro de datos (Datacenter)
Ventajas: Alta velocidad y bajo precio.
Veredicto: Adecuados solo para sitios pequeños o para trabajar a través de APIs oficiales. Las grandes plataformas suelen tener requisitos estrictos de conexión, lo que hace que los proxies de centro de datos sean menos eficaces para tareas de recopilación de datos que consumen muchos recursos.
Especificidad del trabajo con Proxies Móviles en la interfaz
La gestión de los proxies móviles tiene sus características únicas en el área personal. A diferencia de otros tipos, en la ficha de este producto se proporciona un enlace API especial para la rotación (cambio de IP). Debe encontrarlo en la interfaz, ya que es esta dirección la que se utiliza para la actualización automática de la IP dentro de su código de programa o script.

Fig. 1. Ubicación del enlace para rotación automática en la ficha de Proxies Móviles.
Además de la automatización por software, en CyberYozh App se ha implementado la posibilidad de gestión manual. Si necesita actualizar la dirección IP al instante, sin esperar a que se ejecute el script, puede hacerlo con un solo clic directamente en el panel de control.
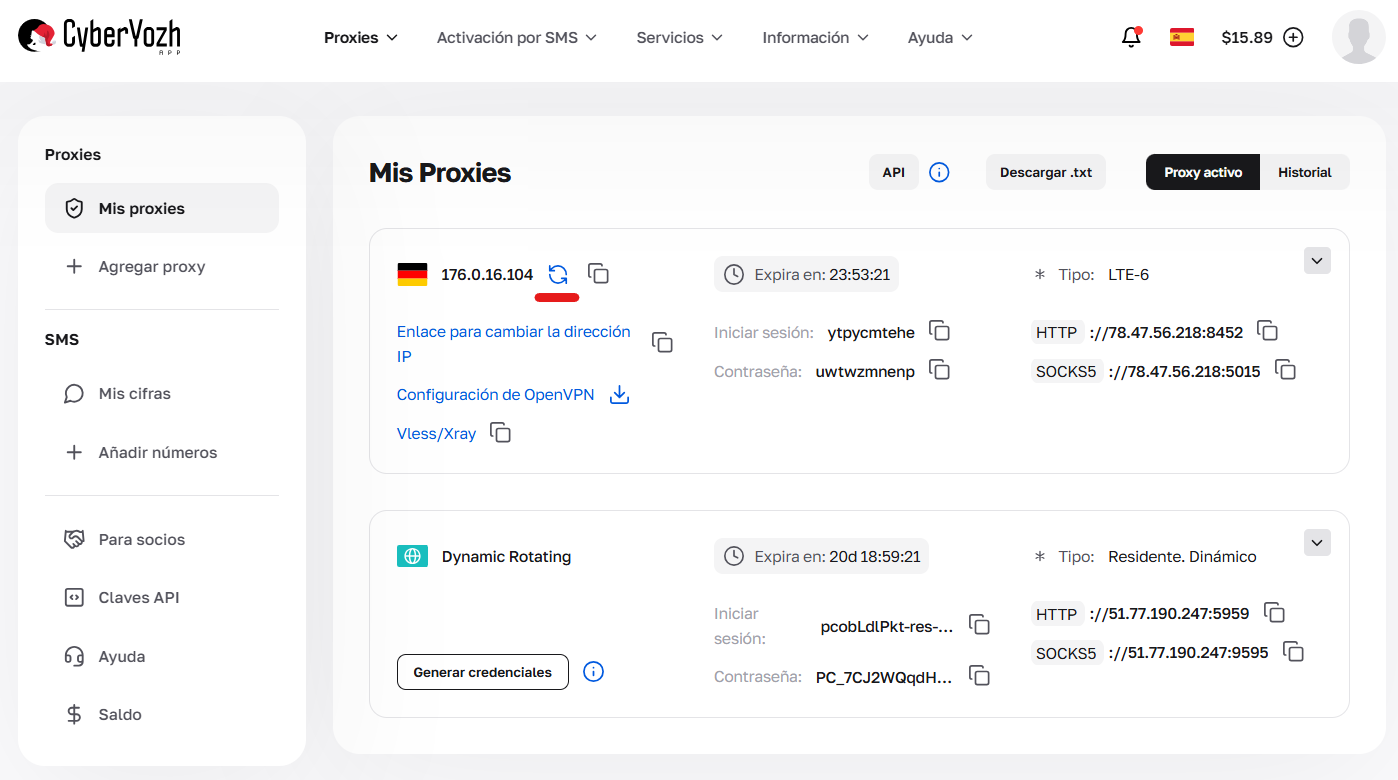
Fig. 2. Botón para el cambio manual forzado de IP en el área personal.
Detalles técnicos: Sesiones, rotación e infraestructura
Elegir el tipo de proxy es solo el principio. Para un scraping profesional, otros parámetros también son importantes.
- Infraestructura de scraping. Recuerde que el proxy es solo una parte del sistema. Un scraping eficaz requiere:
- Un scraper fiable: Un script o programa (por ejemplo, en Python usando librerías como Scrapy, BeautifulSoup, Selenium) capaz de procesar código HTML.
- Gestión de User-Agent y Headers: Su scraper debe estar configurado para trabajar con encabezados dinámicos y rotación de User-Agent para mantener la compatibilidad y estabilidad.
- Manejo de errores: Un mecanismo que gestione correctamente los tiempos de espera y errores, reintentando las peticiones fallidas a través de otro proxy.
La gestión de los proxies residenciales rotativos se ha implementado de la forma más flexible posible. Puede configurar los parámetros manualmente mediante prefijos en el login o utilizar el generador integrado en el área personal.
Gestión a través del área personal (Método recomendado)
Para obtener los ajustes listos, basta con entrar en la sección «Mis proxies» y, en la ficha del paquete comprado, pulsar el botón «Generar credenciales».
En el menú que se abre, puede seleccionar visualmente:
Geolocalización: país, región/estado y ciudad específica (para sesiones largas, solo país).
Tipo de sesión: IP aleatoria, sesión corta (ID de sesión - hasta 1 minuto) o sesión larga (ID de sesión larga - hasta 6 horas).
Protocolo: HTTP o SOCKS5.
Formato de salida: En nuestro generador hay disponibles 3 formatos de salida para copiar fácilmente en cualquier software:
IP:PORT (
IP:PORT:USER:PASS)USER:PASS (
USER:PASS@IP:PORT)PROTOCOL (
http://USER:PASS@IP:PORT)
El generador formará automáticamente la cadena de conexión correcta con todos los prefijos necesarios.
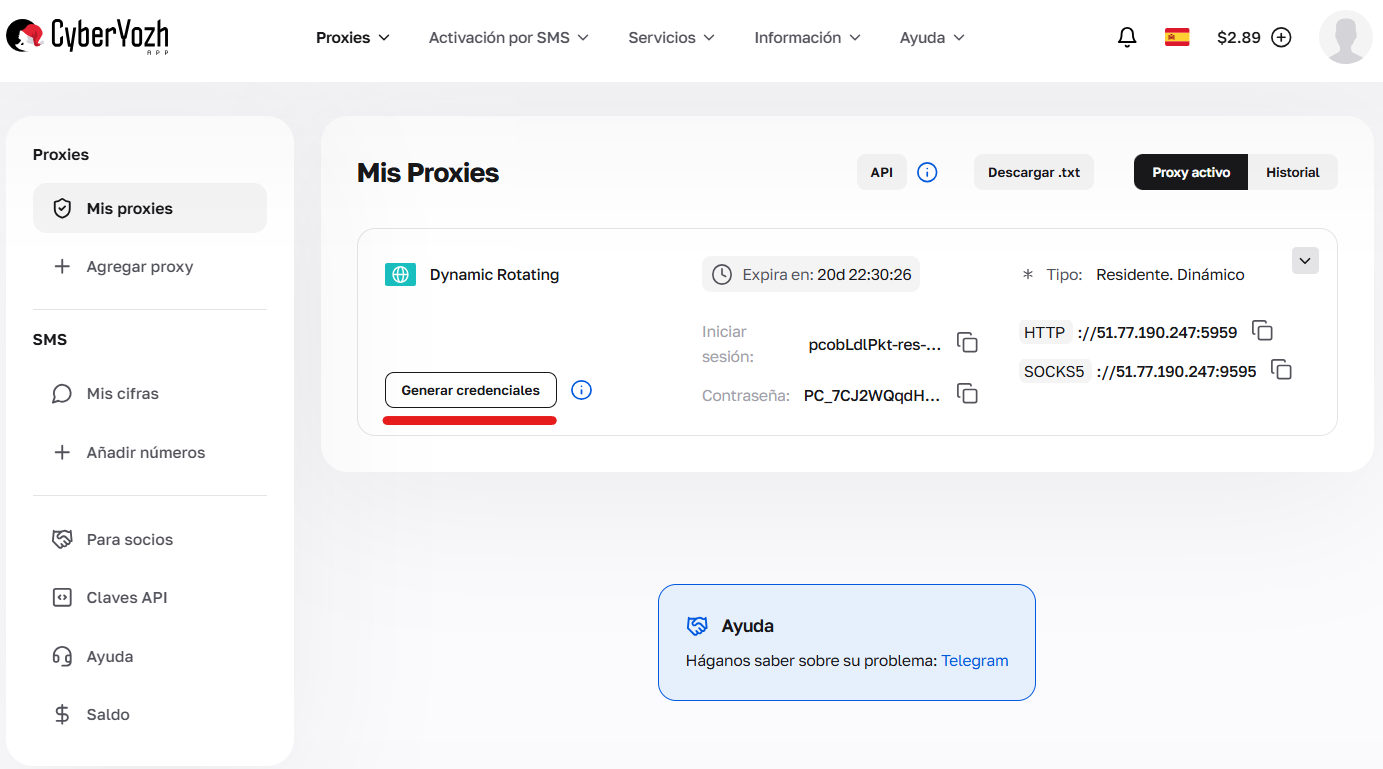
Fig. 3. Acceso a la interfaz de creación de configuraciones y parámetros de conexión (generador de credenciales).
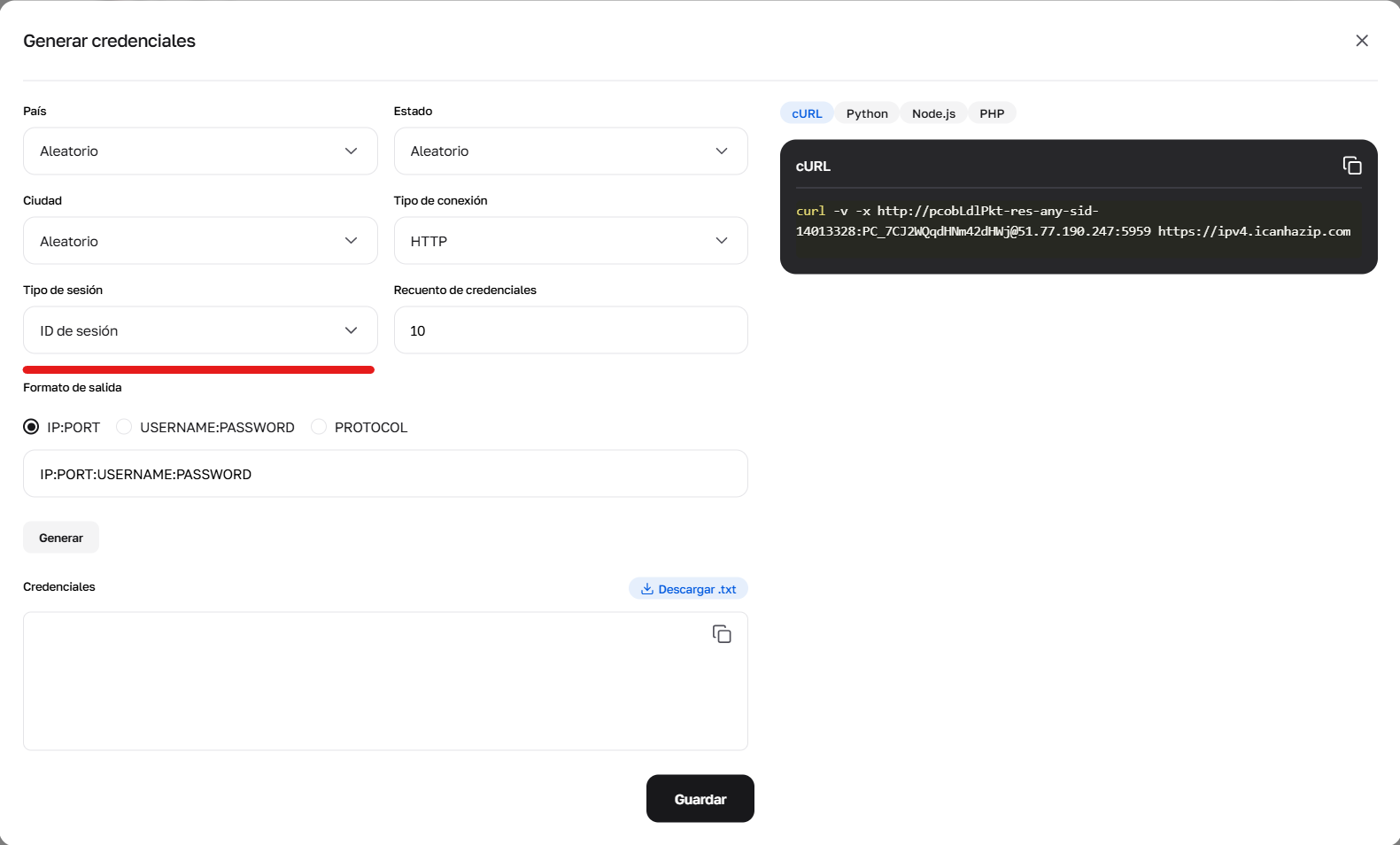
Fig. 4. Uso del generador para configurar el parámetro sid, encargado de crear nuevas sesiones únicas.
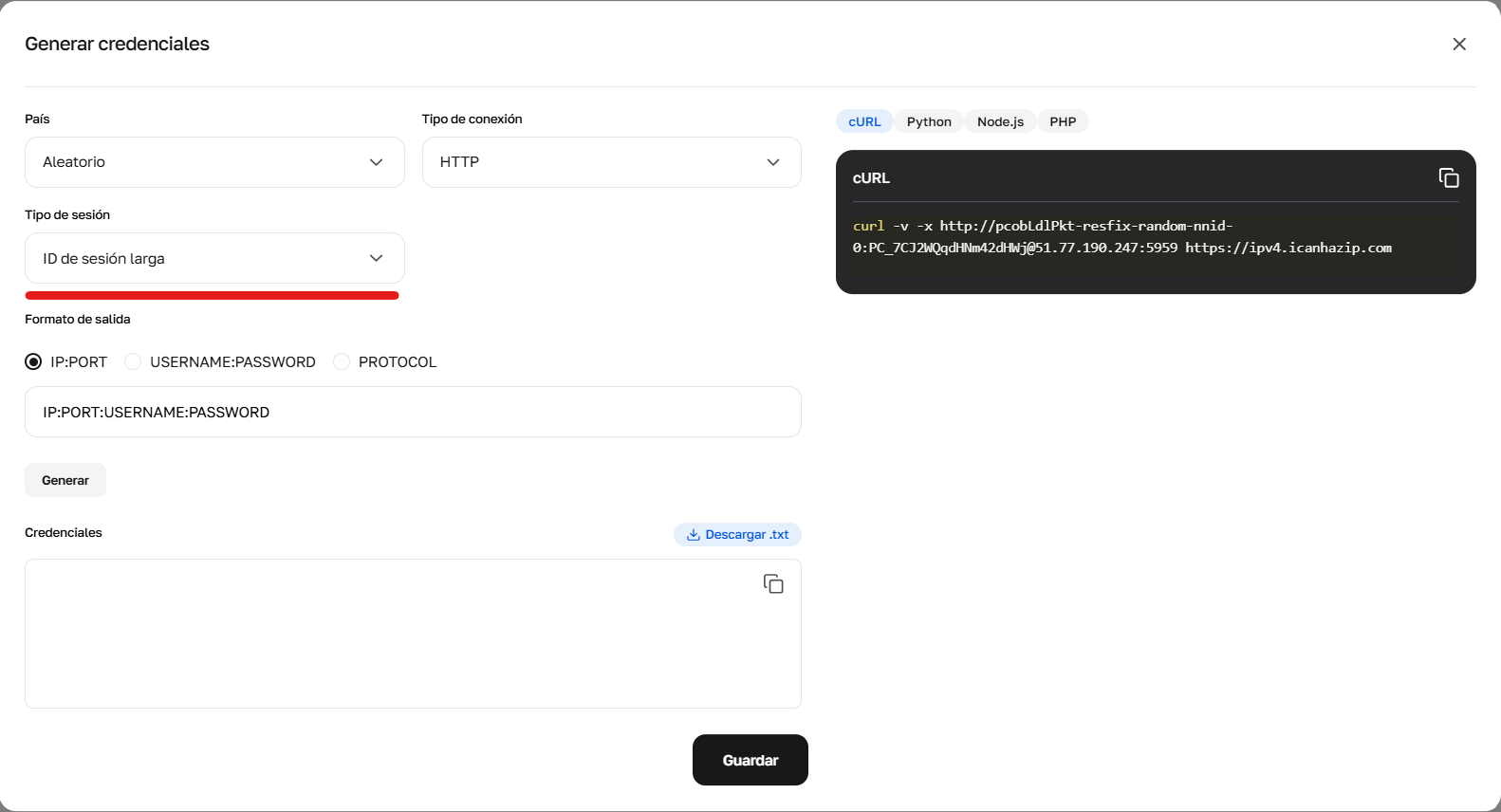
Fig. 5. Configuración de parámetros para la formación de credenciales con el uso de sesiones largas (Sticky).
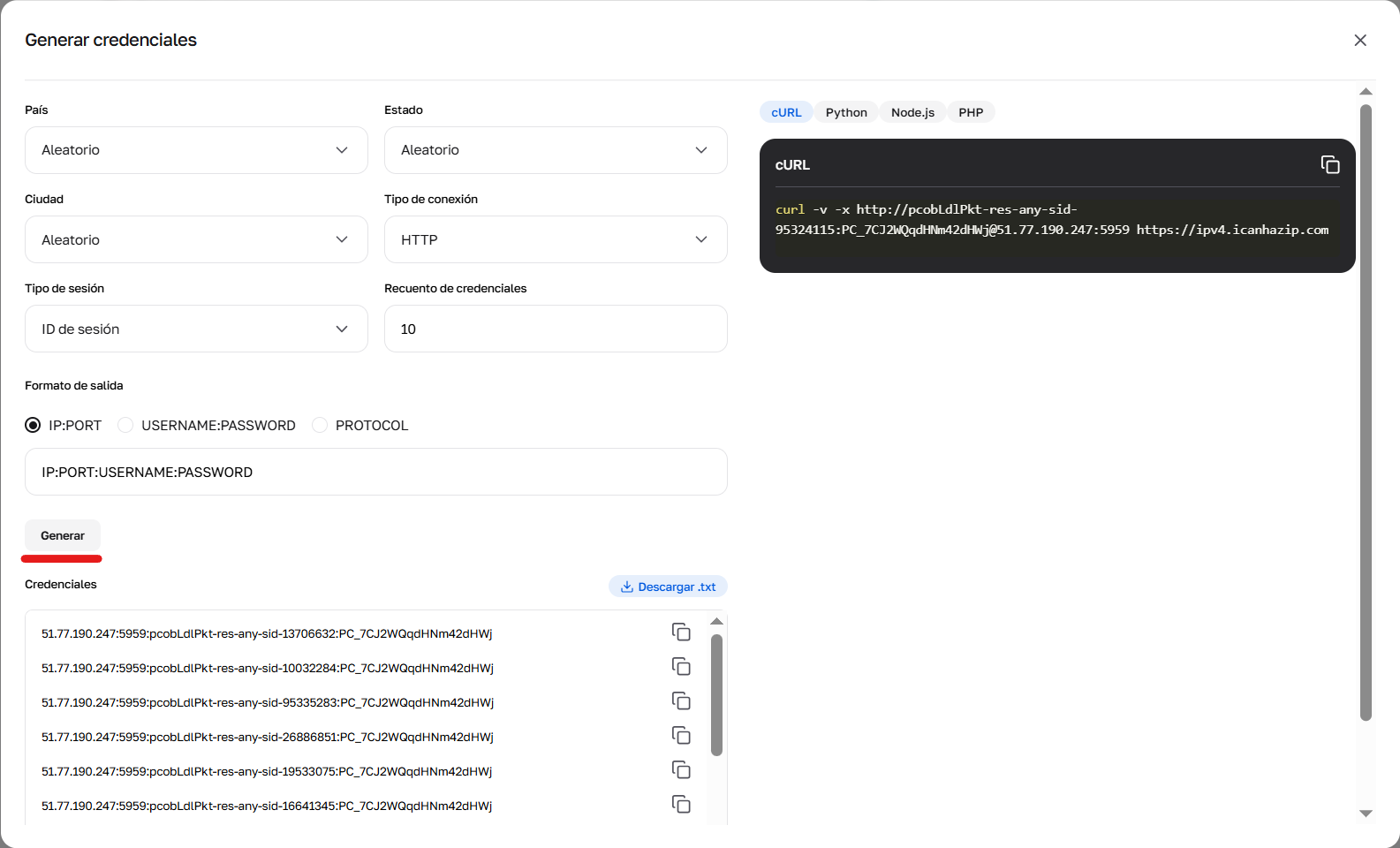
Fig. 6. Resultado del generador de credenciales.
Tipos de sesiones y gestión manual de prefijos
Si está configurando la lógica de cambio de IP directamente en el código de su script, utilice el sistema de prefijos:
| Tipo de sesión | Prefijo en el login | Geo-targeting | Vida útil de la IP |
| IP aleatoria | -res-any | País | Nueva IP en cada petición |
| Sesión corta | -res-any-sid-XXXXXXXX | Ciudad, Región, País | Hasta 1 minuto |
| Larga (Sticky) | -resfix-XX-nnid-TOKEN | País (XX — código de país) | Hasta 6 horas |
Matices importantes de la configuración manual:
Sesiones cortas: En el prefijo
-sid-47551677puede usar cualquier número aleatorio de la misma longitud para la creación instantánea de una nueva sesión.Prefijo geográfico en sesiones cortas: Por ejemplo,
-res_sc-us_georgia_macon-sid-12345dirigirá su tráfico a través de la ciudad de Macon, estado de Georgia.Sesiones largas (Sticky): Para trabajar manualmente, debe obtener el token
X-NN-LLSmediante una petición curl de prueba y colocarlo en el login en lugar de0después de-nnid-. A través del generador en el área personal, este token se coloca automáticamente.
Comprobación de proxy a través del terminal (curl)
La forma más rápida de asegurarse de que todo está configurado correctamente es ejecutar una petición en la consola. Esto permite ver los encabezados técnicos del servidor y verificar el correcto funcionamiento de los prefijos.
1. Comprobación de IP residencial aleatoria
Utilice este formato si necesita una alta rotación (cambio de IP en cada petición):
curl -v -x http://LOGIN-res-any:PASSWORD@51.77.190.247:5959 https://ipv4.icanhazip.com
2. Trabajo con sesión larga (Sticky hasta 6 horas)
Para activar una sesión larga manualmente es necesario pasar por dos etapas:
Etapa A: Obtención del token de sesión Realice la petición indicando 0 en el parámetro nnid:
curl -v -x http://LOGIN-resfix-us-nnid-0:PASSWORD@51.77.190.247:5959 https://ipv4.icanhazip.com
Aquí us es el prefijo del país (USA), que puede sustituirse por el código de cualquier otro país disponible.
Etapa B: Extracción y uso del token
En la respuesta del servidor, busque la línea con el encabezado X-NN-LLS: HTTP/1.1 200 Connection established X-NN-LLS: 9d016e262509d3827293
Copie el token obtenido (9d016e262509d3827293) y colóquelo en lugar de 0 en el login para todas las peticiones posteriores, con el fin de mantener la misma IP: 51.77.190.247:5959:LOGIN-resfix-us-nnid-9d016e262509d3827293:PASSWORD
💡 Consejo: Para no realizar estas acciones manualmente, utilice el Generador de credenciales en el área personal de CyberYozh App. Al elegir "ID de sesión larga", el sistema generará y le proporcionará automáticamente un login listo con el token ya activo para el país seleccionado.
Conclusión: De los datos a la estrategia
La inteligencia competitiva en marketplaces no es magia, es tecnología. Se basa en un proceso de recopilación de datos bien estructurado, y el cimiento de este proceso son unos proxies de calidad y correctamente seleccionados.
Ahorrar en proxies al hacer scraping es el error más costoso, que conduce a datos incompletos, herramientas bloqueadas y, en última instancia, a decisiones de negocio erróneas. Invierta en una infraestructura fiable y obtendrá acceso a la información que se convertirá en su principal baza en la lucha competitiva.
👉 ¿Busca una solución fiable para el scraping? Nuestros proxies residenciales rotativos ofrecen acceso a millones de IPs limpias en todo el mundo con una gestión flexible de sesiones. Es la herramienta ideal para recopilar datos de cualquier marketplace, incluso de los más protegidos.
